(Originally posted 2012-10-13.)
Hackday X was good clean fun yesterday – though I think it deserves more than one kiss. 🙂
Seriously, for once I think I have a hack that actually worked – at least up to a point.
I called my entry “z/OS Batch Analytics Baby Steps” and I think that’s about right. My purpose in taking part in successive Hackdays has been more to participate rather than to win any prizes, and to wave the flag a little for System z hackers. And to get some stuff done, experimental stuff I probably couldn’t afford to try out in my day job: The code enhancements I do there are more focused on the customer situation in hand or some annoyance or idea deriving from a real situation. With Hackday I can be more “out in left field” with what I try to do.
Actually having something to show for it would be nice. And in this case I could probably make it usable “in Production” in a couple more hours. But I wonder though if you think “usable” really means “valuable”. But first a recap of an oft-repeated rant.
Batch Analytics
I’ve said many times, including in this blog, that installations (and casual visitors such as me) know far too little about how batch runs.
While everyone has some batch reporting, and I have quite a lot of it, I think there’s a long way to go.
Here’s a good example, and one I chose to address with this hack:
While I might list job names and their run times it’s hard to see more than the most obvious of patterns. I choose to adopt the term “Analytics” here as a direction of travel as patterns are a part of it. At this point I’m going to suggest you read a recent post of mine: Games You Can Play With Timestamps and spend my column inches in this post talking about the actual hack.
So, in case you were in any doubt, “Batch Analytics” in this post refers to “Analytics of Batch”, rather than “Analytics run in Batch mode”.
The Hack Itself
Consider:
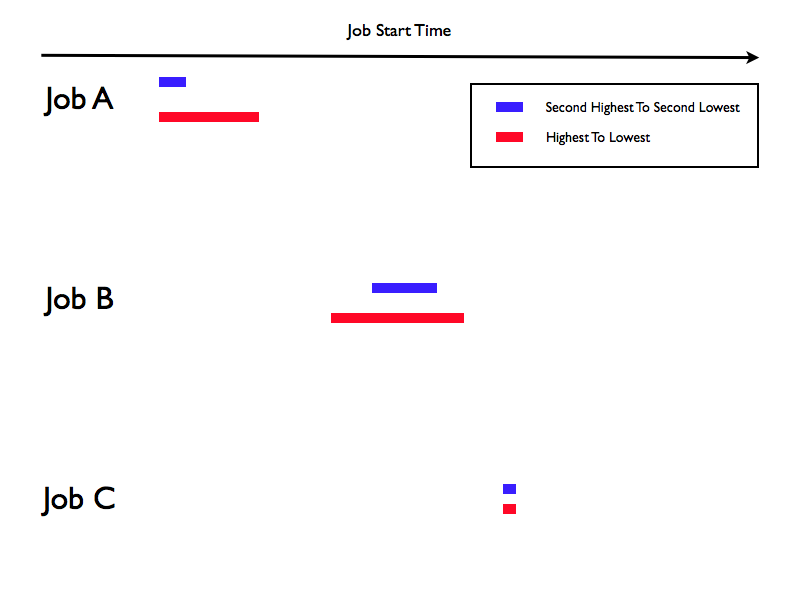
This is, with the exception of the colouring, what my hack produced.
There are three jobs and I plot their start times, over a number of days. Actually I don’t: The red bars depict the earliest start time through to the latest. The blue bars depict the second earliest through to the second latest. In my test data I had five days of data so many jobs ran five times, some ran only once and one ran ten times. Next to the job name I print the number of times I saw the job run. (I also have a proper start time axis across the top.)
Though this is made up data the real data sample looked pretty similar:
- There were many jobs much like Job A and Job B, with lots of variation in start time.
- There were some jobs (mainly towards the front of the schedule) like Job C – with very little start time variation.
I think in the fullness of time I can do much better: This prototype uses Bookmaster Schedule tags to create a Gantt Chart. It’s monochrome and I think I’ve almost exhausted what it can do. But it was quick to code up and illustrates a point: Visualisation of job run times can be helpful.
The raw data is, of course, SMF Type 30 Subtype 5 Step-End records – and for once I didn’t need to change how the performance database is built. So the new bit is just more REXX code.
Futures
There are at least two things I can think of that would be better visualisations, though creating the apparatus to graph them would be a bit of a challenge. So I mocked up two possible graphs. While these graphs are almost identical they bear no relation to the one above.
The simpler, and perhaps more consumable one in practice is:
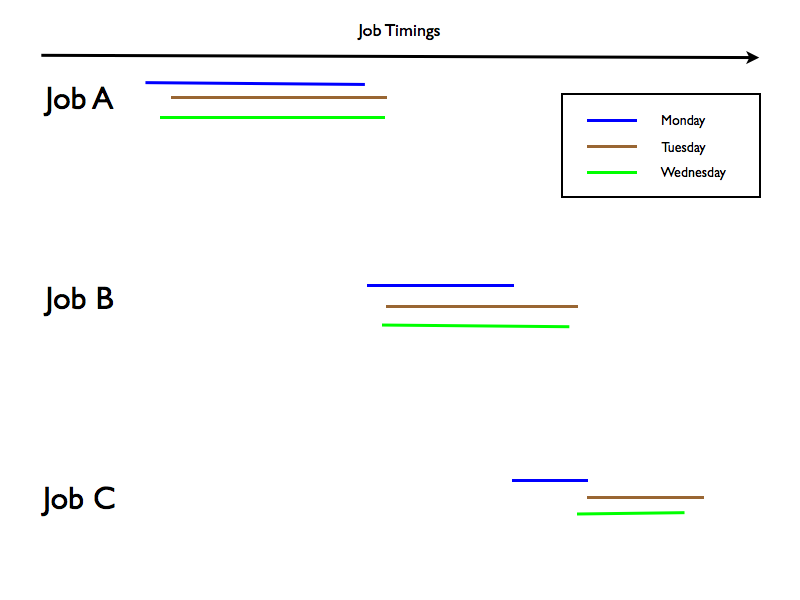
In this one I plot both the start and end times for each job’s runs, with a different colour bar for each day the job ran.
This could show you the variance in start times and in end times.
It might be possible to produce it using bar charts with clever usage of invisible bars in the stacks but marking hours and minutes on the axis would be a nuisance. It might be easier to generate some HTML5 Canvas code (javascript) to create the whole thing.
Now consider an enhancement – which in practice might get messy:
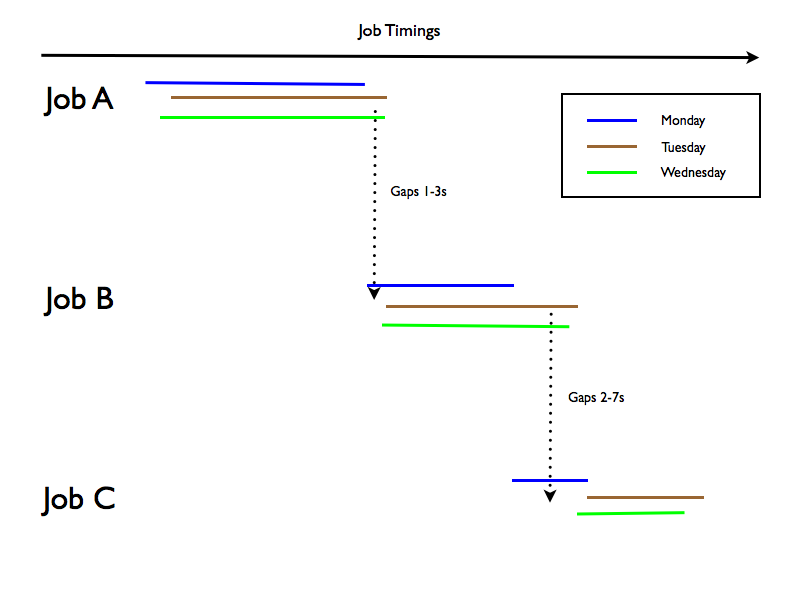
In this example the code would calculate the gaps between e.g Job A finishing and Job B starting and annotate the picture with it.
The calculations (as I mentioned in Games You Can Play With Timestamps) are very easy.
My concern about this is that the number of “gaps” annotations on a picture like this would grow to be huge very rapidly. Maybe some “smarting” that only annotates if the gaps between 2 jobs tend to be less than 5 seconds would help here.
It’s too tempting a goal to abandon entirely. And I can think of other wrinkles like annotating when jobs are consistently seen to start together.
But after a good day’s hacking I returned to the day job: A large mount of (non-batch) performance data arrived and duly got built into databases. And I’m looking forward to gaining insight into that customer’s systems over the next few days. But Hackday X was a great chance to explore some of the themes in (you guessed it) Games You Can Play With Timestamps which had been rolling around in the back of my mind. (You can imagine maintaining discipline to focus on less speculative stuff until Hackday itself was quite difficult – but I managed it somehow.)
But then that’s what Hackday is all about: Releasing untapped ideas into the wild and building prototypes that can be built upon later. If you ever get a chance to do something similar in your company do take it – it’s very rewarding but frustrating in that you only get a little time.
