Wouldn’t you like to know where in the machine an LPAR’s memory is? Perhaps not but for some customers it’s more than a matter of idle curiosity.
The good news is that RMF will be able to tell you: A recent APAR for z/OS 3.2 Data Gatherer OA68545 exploits information from z17 processors to provide precisely this information.
As I write this “will be able to” seems appropriate – as most customers are either not at z/OS 3.2 or not on z17. Of course the APAR is a further requirement – so subject to maintenance yet to be applied.
Why You Might Want To Know
In a single drawer machine the location of an LPAR’s memory might not be all that important to know.
It’s when the machine has more than one drawer that you might like to know:
- If you reckon you have an LPAR split across drawers you’d want to know if the logical cores were split or whether it was the memory. And during an LPAR drawer swap the cores move immediately and the memory takes time to move.
- If you are adding LPARs or increasing their memory footprint you probably want to know if there is any threat of cross drawer or of PR/SM having to rework LPAR resource placement.
- You might want to explain why one LPAR is in one drawer and another is in another – when there are few enough cores between them to fit in one drawer.
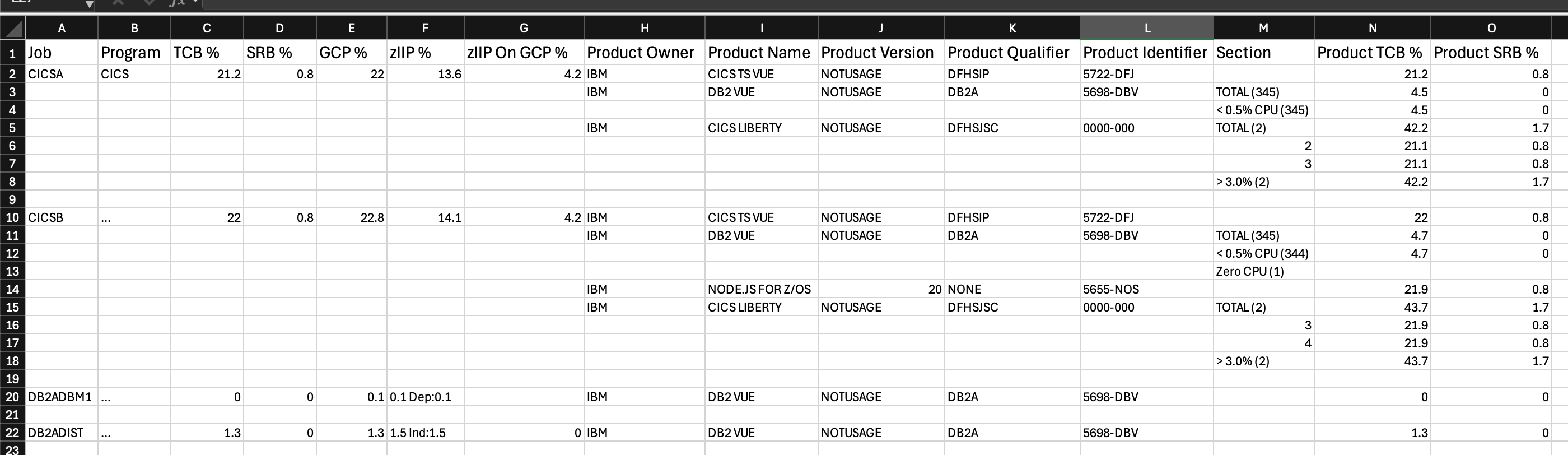
What The APAR Gives You
This new APAR deals in memory increments.
It gives you the increment size and how many increments the LPAR has at each approximate location.
By “approximate location” it is certainly enough to tell you how much is in which processor drawer. It’s actually down to what is known as a “node” – which I think is a DCM.
What you don’t get is any kind of address – but I don’t yet see that as a shortcoming.
In my first (internal) set of data I see how “PHYSICAL” is treated: You can’t tell how much purchased memory is in each drawer. This is a bit of a shame. From Vital Product Data I get quite a good view of this, by the way. But most people don’t have access to that. It’ll remain in the category called “a stunt Martin pulls” – which isn’t actually a category I want it to be in.
I don’t expect the information to include anything to do with Virtual Flash Memory or anything outside customer addressable memory. My one set of data – as I write this – doesn’t include a machine with VFM defined for any of the LPARs.
There is a new record subtype to deal with: SMF 70 Subtype 3. So this isn’t crammed into the already rather complex SMF 70 Subtype 1. I think that’s sensible.
I know CP3000 Development has worked to support this – and I expect the IntelliMagic team to be swift in supporting it. For my part, the record volume is going to be quite low so I can write REXX against the records and expect good performance. I’m increasingly writing REXX code to process raw SMF records, sometimes with Python post-processing the results.
(As an aside, REXX has been able to process VBS records such as SMF since z/OS 2.1.)
Right now I’ve eyeballed – using ERBSCAN and ERBSHOW – the one set of data I’ve got but I haven’t written the REXX; You know I’m itching to.
Conclusion
You will probably have spotted – as I’ve talked about it enough – that SMF 70 Subtype 1 brought Logical Processor home addresses to our instrumentation kitbag. And it did it for all LPARs on the machine. That made this instrumentation better than SMF 99 Subtype 14.
This new support does the same thing for memory.
It will be interesting to see what stories it enables us to tell. But already I have some ideas.
It’s just that at the time of writing I’ve only seen a z/OS 3.2 system, let alone one running on z17. As so often happens, it’s an internal system – so I await a real customer system. I definitely have customer situations that could’ve done with this.
One caution: You can’t necessarily predict what PR/SM might do but sensible LPAR Design can be informed by good instrumentation.
Making Of
I again don’t remember where I started this post but I’m finishing it off on a flight to South Africa. C’est la vie.
Time to publish a few.