(Originally posted 2013-11-08.)
Usually a residency ends on the last day. Well doesn’t everything? 🙂
But this one’s been a little unusual in that regard. Straight after the residency came a week in which two of us presented at the GSE UK Annual Conference on aspects of the residency:
- Dean Harrison presented on Scheduling and JCL aspects.
- I presented on Performance aspects.
And Karen Wilkins, the other resident, was working the DB2 stream.
So, we got a chance to test reactions to some aspects of the book. We also collected a couple more reviewers.
I won’t mention any names here but my session in particular “lit up” when it came time to questions. And these got me thinking (which is why I love getting questions).
There was a question about I/O bandwidth and increased parallelism. Yes, I think that has to be analysed and managed. And I should probably write something in the book about it. In our tests we didn’t actually manage to drive I/O in a way that caused time to be spent in the DB2 I/O-related Accounting Trace buckets. But I don’t feel bad about that as it’s impossible to construct an example that exemplfies everything and the technological lessons are fairly straightforward to grasp. (For reference they are in the area of I/O reduction and dealing with the remaining I/O hot spots in the usual ways.)
There was a question about examining the whole environment into which you thrust this cloned workload. Again I should probably write something in the book about it.. And in our case it mattered because, not to spoil the story, the 32-up cloning cases led to CPU Queuing which limited our ability to scale effectively.
These two are actually questions I’ve addressed in previous Batch Performance Redbooks. So I don’t want to repeat myself very much. But they are important for cloning.
There was a third question which is worth addressing:
- Is there really anything new in this? The answer is: Not really, but people are increasingly going to have to pay attention to it, plus we have some nice techniques in the book (and Dean explained some of those in his presentation). We did the book because one is needed.
There was a fourth question or rather theme. We rather dodged it in the book. It’s really about how to treat whole strings of jobs. And I should probably write something in the book about it.
But it’s mainly about when to (and how to) “Fan Out” and “Fan In”.
When To Fan Out And When To Fan In
In the book we simplify things by writing about a single original job step that needs cloning. While that’s the right thing to do there are important considerations at the “stream of jobs level”.
Consider the following simple set of 4 jobs:
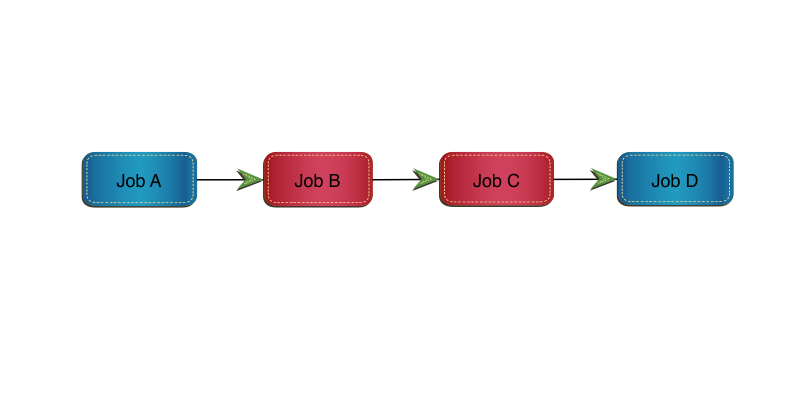
Job A and Job D won’t be cloned for now. Job B and Job C will.
Here’s a naive implementation of what we recommend in the book:
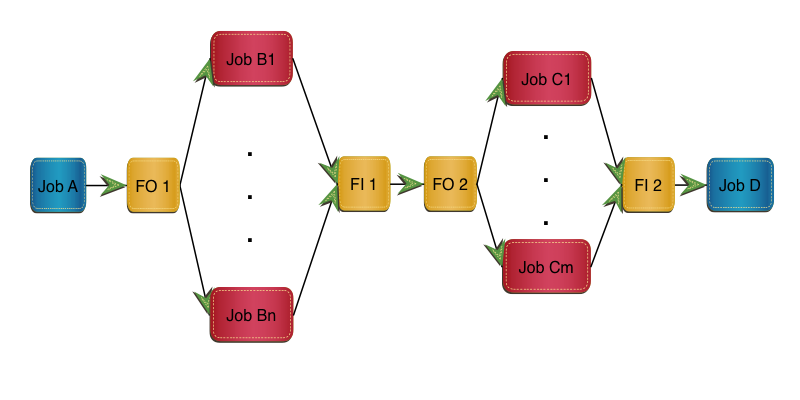 In this implementation Job B is replaced by FO 1, m clones and FI 1.
Job C is replaced by FO 2, n clones and FI 2.
In this implementation Job B is replaced by FO 1, m clones and FI 1.
Job C is replaced by FO 2, n clones and FI 2.
I don’t doubt we need FO 1 to fan out and FI 2 to fan in again, though both of these might be null. But do we really need to fan in after the Job B clones, only to fan out again before the Job C clones? There are a few reasons why we might not:
- From a scheduling point of view we wait for all the Job B clones to complete before we can start any of the Job C clones.
- Bringing data back together might be expensive.
- There are lots of moving parts here.
And that’s with just two jobs being cloned in the stream.
How Many Clones?
You’ll notice there are n clones of Job B and m clones of Job C. It’s probably best to standardise on one or the other for the stream. That might be a difficult judgement to make, based on each job’s cloning “sweet spot”. And it might turn out that actually n=2m is better than n=m, for example.
Data Sets Flying Everywhere
Another difficult judgement to make is how to handle inter-job data. This gets complicated very fast and has to be taken on a case by case basis – so I won’t inflict more diagrams on you. 🙂
As a relatively simply example we might need to write consolidated data in FO 1 to data set DSA (for some external purpose). I don’t see that as being avoidable but that needn’t stop the Job C clones. With care (and maybe technology) FI 1 might run alongside the Job C clones:
If Job C read data set DSA that Job B wrote then Job C1 might need to read data set DSA1 that Job B1 wrote, in parallel with FI 1 reading it. (Job FI 1 has to recreate data set DSA, in this scenario.)
Likewise Job Cn needs to read DSAn that Job Bn wrote, in parallel with FI 1 reading it.
The most obvious difficulty here is contention between the Fan In job (FI 1) and the readers (C1 … Cn). Whether this is serious or not depends on things like the quantity of data written.
One Obvious Scenario
One scenario I can see the “when to fan in and out” question coming up in is during the actual implementation: Job A might be cloned but the follow-on Job B not yet and its follow-on Job C not yet. It’s probably best to clone Job A then Job B then Job C (or all three at the same time). Cloning Job A and Job C but not yet Job B is not so good. So extend the sequence of cloned jobs outwards rather than doing it spottily.
See, I used the word “simplify” a while back: This stuff gets complicated very fast. And I don’t know how much complexity is worth delving into. The previous section is a first go at handling it. Any deeper and I don’t think we help the reader. (That’s you.) 🙂
I bolded the words “I should probably write something in the book about it” when I wrote them because it’s a key message from the GSE Conference: We have more work to do. I turns out I have the latitude to do just that, with the writing tools on my laptop, and perhaps a little time (some of it likely to be on aeroplanes).
The conventional wisdom is that when the residents go home no more writing can be done. That’s probably a fair assumption but in this case I think it’s a little pessimistic. Or at least I hope so.
I’m tremendously proud of what Dean, Karen and I have achieved over our four weeks in Poughkeepsie. If you read the book, even in the state it’s in now, I think you’ll like it.
Technically we probably could go on for ever, adding stuff to it. One day that’ll have to stop – as we really do want to get the book out soon. (And actually I’d rather like to work with some customer applications in the vein of what we’ve written – but I don’t control my workload enough to insist that happens soon.) But for now the writing goes on.
Now where can I shove some more “Galileos”? 🙂
