(Originally posted 2014-11-16.)
In After A Decent Interval I talked about the need for frequently-cut SMF Interval records. This post is about bad behaviours (or maybe not so bad, depending on your point of view).
It’s actually an exploration of when interval-related records get cut, which turned into a bit of a “Think Friday” experiment. But I think – quite apart from the interest – it has some usefulness in my “day job”.
I share it with you in the hope you’ll find it interesting and perhaps useful.
And it’s in some ways related to what I wrote about in The End Is Nigh For CICS.
Code To Analyse SMF Timestamps
Let’s start with a simple DFSORT job to analyse the minutes when SMF 30 records are cut – in the hour. It’s restricted to looking at SMF 30 Subtype 2 Interval records. These are the 30’s one would most expect to have cut on a regular interval. (Subtype 3 records are cut when a step ends – to complement the Subtype 2’s.)
In reality the analysis I’m sharing with you uses more complex forms of this basic job. But we’ll get on to the analysis in a minute.
The first step is very simple and deletes a report data set. The second step writes to this data set and, identically, to the SPOOL. [1]
The INCLUDE statement throws away all record types other than SMF 30 Subtype 2.
The INREC statement turns the surviving records into two fields:
- The record’s time in the form hhmmss, for example ‘084500’ for 8:45AM.
- A 4-byte field with the value ‘1’ in.
These two fields are used in the SORT statement to sort by the minute portion of the timestamp and the SUM statement to count the number of records with a given minute.
The purpose of the OUTFIL statement is to format the report for two destinations. It produces a two-column report. The first is the minute and the second the number of records whose timestamp is within that minute. For example:
MIN Records
--- -----------
00 49844
01 23
02 45
.. ..
Here’s the code.
//DELOUT EXEC PGM=IDCAMS
//SYSPRINT DD SYSOUT=K,HOLD=YES
//SYSIN DD *
DELETE <your.report.file> PURGE
IF MAXCC = 8 THEN SET MAXCC = 0
/*
//*
//HIST EXEC PGM=ICEMAN
//SYSPRINT DD SYSOUT=K,HOLD=YES
//SYSOUT DD SYSOUT=K,HOLD=YES
//SYMNOUT DD SYSOUT=K,HOLD=YES
//SYMNAMES DD *
* INPUT RECORD
POSITION,1
RDW,*,4,BI
SKIP,1
RTY,*,1,BI
TME,*,4,BI
SKIP,4
SID,*,4,CH
WID,*,4,CH
STP,*,2,BI
*
* AFTER INREC
POSITION,1
_RDW,*,4,BI
_HOUR,*,2,CH
_MIN,*,2,CH
_SEC,*,2,CH
_T30,*,4,BI
//SYSIN DD *
OPTION VLSCMP
INCLUDE COND=(RTY,EQ,+30,AND,STP,EQ,+2)
INREC FIELDS=(RDW,TME,TM1,X'00000001')
SORT FIELDS=(_MIN,A)
SUM FIELDS=(_T30,BI)
OUTFIL FNAMES=(SORTOUT,TESTOUT),
OUTREC=(_RDW,X,_MIN,X,_T30,EDIT=(IIIIIIIIIT)),
HEADER1=('MIN',X,' RECORDS',/,'---',X,'----------')
//TESTOUT DD SYSOUT=K,HOLD=YES
//SORTIN DD DISP=SHR,
// DSN=<your.input.data.set>
//SORTOUT DD DISP=(NEW,CATLG),UNIT=PM,RECFM=VBA,
// SPACE=(CYL,(1,1),RLSE),DATACLAS=FASTBAT,
// DSN=<your.report.file>
Of course you’ll need to fiddle with things like the DATACLAS parameter and which output class you use. I’m assuming that’s within the skill set of anybody reading this post.
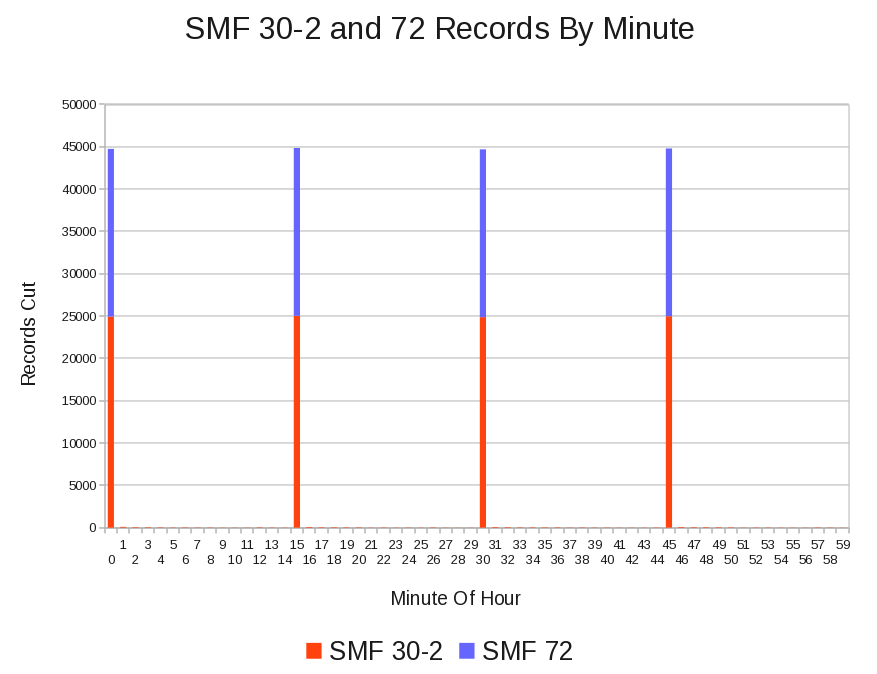
A “Well Behaved” Case
The following graph is from a customer whose SMF 30–2 and RMF records all appear, regular as clockwork, every 15 minutes. I’m showing SMF 72 (Workload Activity) records stacked on SMF 30–2 – as these are of similar volumes. [2]
In reality a few 30–2 records are cut every minute but no RMF records are cut “off the beat”.
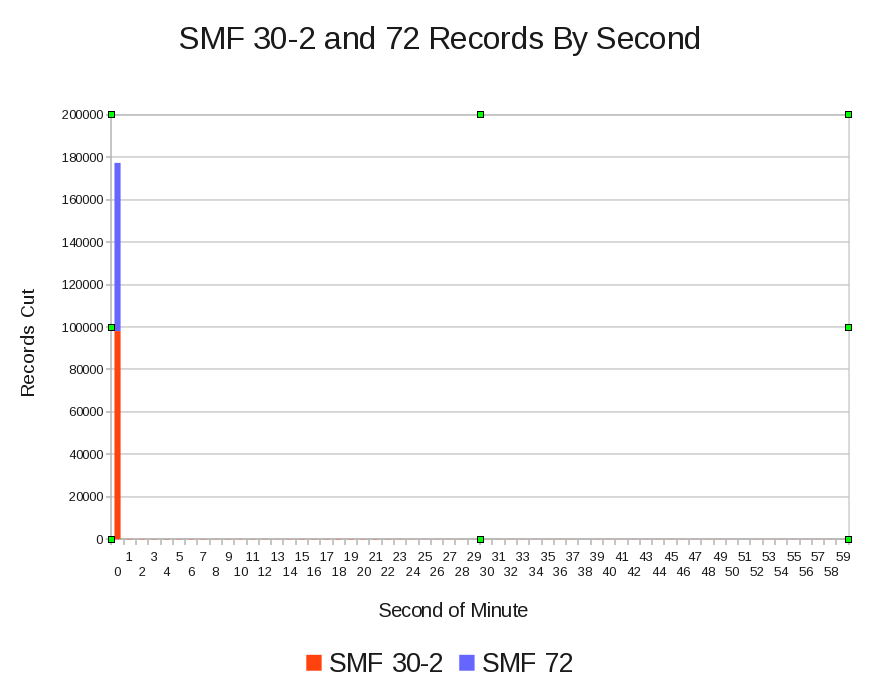
Drilling down to seconds, as the next graph shows, almost all the records are cut in the first second of the minute – both SMF 30–2 and 72. [3]
A Less Tidy Case
Contrast the above example with another customer, whose data is less well behaved. [4]

In this case the RMF records are all cut “on the beat”; It’s the SMF 30–2 records that aren’t.
In fact this is data from just one system out of many.[5]
In the previous case I surmise Interval Synchronisation was used (SYNCVAL and INTVAL parameters in SMFPRMxx) but in this case my best guess is that it isn’t.
Looking at Reader Start Times (which are in each Interval record, just as they are in Subtypes 4 and 5 for Step- and Job-End recording), the time when an SMF 30 is cut is determined by when the address space started.[6]
Let’s drill down a little, using field SMF30WID in the SMF Header; It gives the subsystem as SMF (and SMFPRMxx in particular) sees it:
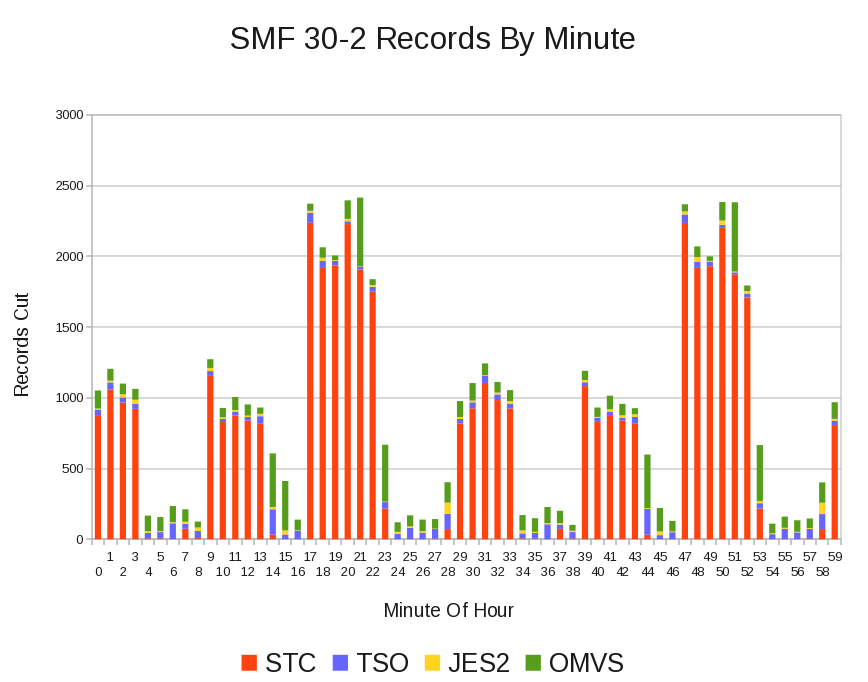
Superficially it looks as if the SMF interval is 10 minutes; It isn’t. It’s actually 30 minutes. The high peaks are thirty minutes apart but there is something going on every 10 minutes, affecting STC and probably OMVS. It’s something I’ll want to discuss with the customer.
Conclusion
You might ask why I care about this sort of thing.
Partly it’s curiosity, sparked in this case by occasional glimpses that things aren’t as simple as they appear: If you really want to believe Interval records are tidily cut on interval boundaries that’ fine – but occasionally the fine (or not so fine) structure will up and bite you.
In my case the code I use occasionally produces bad graphs because it summarises records on 15, 30, or whatever minute intervals and records fall into the wrong interval. I’d like to at least be able to explain it.
But more generally, I have to pick a summarisation interval. Understanding how frequently and tidily Interval records are cut enables me to do that. I’m going to put code to do a basic form of this analysis into our process – right after we fetch the raw SMF from where you send it to (ECUREP, probably). This will save no end of time – as rebuilds of our performance databases and reruns of reporting can be reduced.
And, if nothing else it’s prompted me to re-read the SMFPRMxx section in z/OS Initialization And Tuning Reference.
Now that can’t be a bad thing. 🙂
-
That’s what the OUTFIL FNAMES parameter achieves. ↩
-
In my Production code I actually break down by SMFID and by record type in the range 70 to 79. ↩
-
In a busier or bigger system it might take more than 1 second on an interval to cut all the records; I look forward to seeing if that’s the case. ↩
-
It’s not really a moral judgment, but I expect this sort of data to cause more problems. ↩
-
My actual Production code report by system – in order to see the differences at a system level. ↩
-
Thanks to Dave Betten and some SMF 30 code of his it’s possible for me to see the Reader Start Time – which isn’t in the SMF Header and so can’t rigorously be processed by a simple DFSORT job. ↩
