(Originally posted 2017-07-14.)
If a customer has Transaction goals[1] – for CICS or IMS – it’s possible to observe the CPU per transaction with RMF.
But you have to have:
- Transaction rate
- CPU consumed on behalf of the transactions.
This might seem like stating the obvious but it’s worth thinking about: The transaction rate and the CPU consumption have to be for the same work.
Now, a Transaction service class doesn’t have a CPU number. Similarly, a Region service class doesn’t have transaction endings.
So you have to marry up a pair of service classes:
- A Transaction service class for the transaction rate.
- A Region service class for the CPU.
Operationally this might not be what you want to do. Fortunately, you can do this with a pair of report classes.
There’s another advantage to using report classes: You can probably achieve better granularity – as you can have many more report classes than service classes[2].
So I wrote some code that would only work if the above conditions were met[3].
Unimaginitively my analysis code is called RTRAN; You feed it sets of Transaction and Region class names.
Perhaps I should’ve said you could have e.g. a pair of Transaction report classes and a single Region report class and the arithmetic would still work[4].
But why do we care about CPU per Transaction?
There are two reasons I can think of:
- Capacity Planning – by extrapolation
- Understanding what influences the CPU cost of a transaction
From the title of this post you can tell I think the latter is more interesting. So let’s concentrate on this one.
In what follows I used RTRAN To create CSV files to feed into spreadsheets and graphs[5]. Over the course of a week I captured four hills while developing RTRAN.
The first thing to note is that CPU per Transaction is not constant, even for the same mix of transactions.
This might be a surprise but it makes sense, if you think about it. But let’s think about why this could be.
Two Important Asides
But first a couple of asides on this method:
- Take the example of a CICS transaction calling DB2. While most of the work in DB2 is charged back to CICS not all is: There is a significant amount of CPU not charged back[6]. It’s highly likely the DB2 subsystem is shared between CICS and other workloads, such as DDF and Batch; It gets much less satisfactory trying to apportion the DB2 cost so I simply don’t.
- Likewise, I’m ignoring capture ratio. While it would be wrong to believe it’s constant, for most of customers’ operating range it’s a fair assumption to go with a constant value for capture ratio.
In a nutshell, both these asides amount to “this is not a method to accurately measure the cost of a transaction but rather to do useful work in understanding its variability.”
Why CPU Per Transaction Might Vary
I’m going to divide this neatly in two:
- Short-Term Dynamics
- Long-Term Change
Short Term Dynamics
CPU per transaction can, demonstrably vary with load. There are a couple of reasons, actually probably more. But let’s go with just two:
- Cache effects, that is more virtual and real storage competing for the same scarce cache.
- If a server becomes heavily loaded it might well do more work to manage the work.
But it’s not just homogenous variation; Batch can impact CICS, for example.
Look at the following graph:
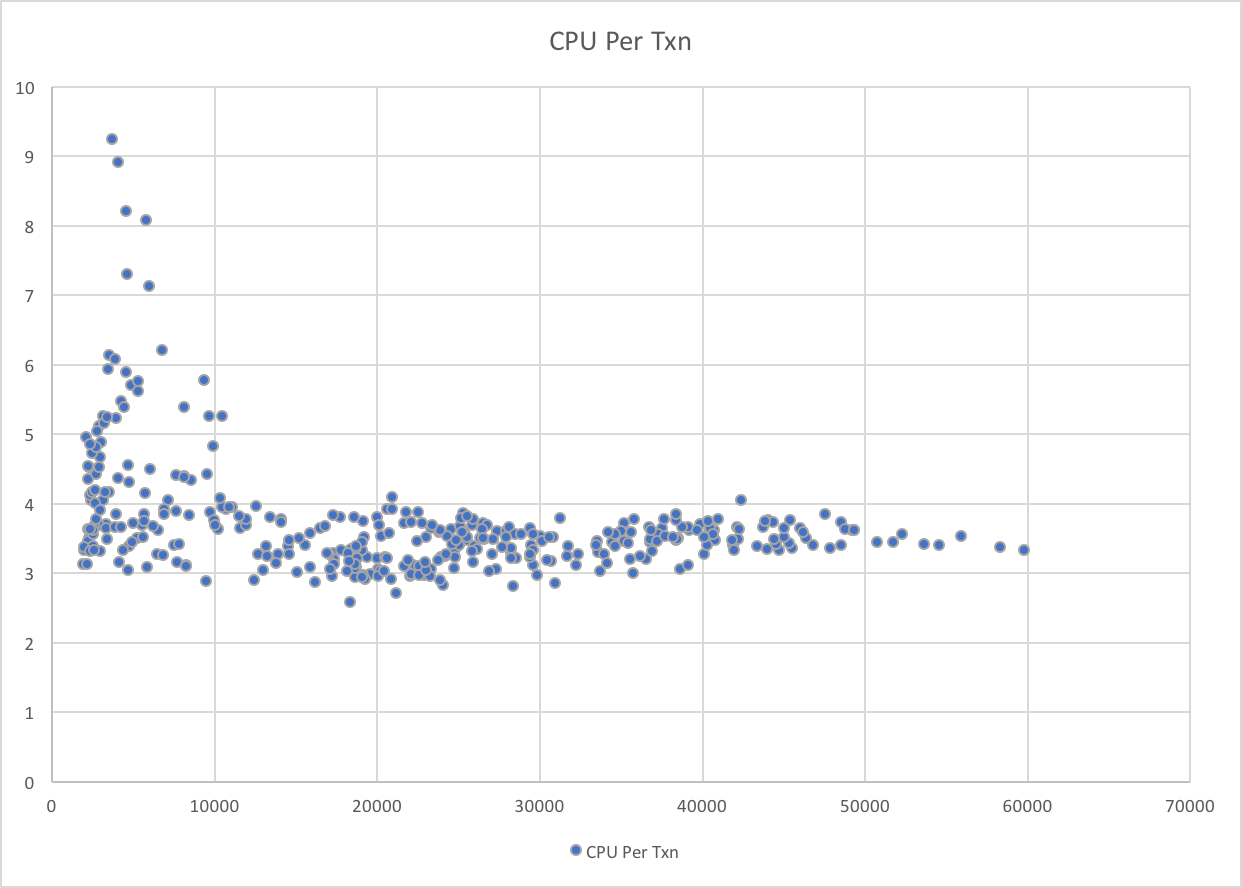
In this case it’s the lower transaction rates that are associated with the higher CPU per transaction. But not all low transaction rate data points show high CPU per transaction.
A tiny bit more analysis shows that the outliers are when Production Batch is at its heaviest, competing for processor cache. It’s also the case that these data points are at very high machine utilisation levels, so the “working more to manage the heavy workload” phenomenon might also be in play.
Long Term Change
“The past is a foreign country; they do things differently there” L. P. Hartley The Go-Between.
Well, things do change, and sometimes it’s a noticeable step change, like the introduction of a new version of an application, where the path length might well increase. Or, perhaps, a new release of Middleware[7]. Or, just maybe, because the processor was upgraded[8].
But often, perhaps imperceptibly, CPU per transaction deteriorates. For example, as data gets more disorganised.
Conclusion
If it’s possible to do, there’s real value in understanding the dynamics of how the CPU per transaction number behaves.
Try to understand “normal” as well as behavioural dynamics, and watch for changes.
-
With CICS and IMS you can have two main types of service classes – Region and Transaction. In the case of the latter, WLM manages CPU in support of the Transaction service class’ goals rather than the (probably velocity) goal of the Region service class. Note: You can have multiple Transaction service classes for the one CICS region, despite it only having only one Quasi-Reentrant (QR) TCB. ↩
-
And there’s no performance penalty for doing so. ↩
-
I’m hopeful I can persuade customers to think about their service / report classes with the above in mind. ↩
-
Perhaps that’s stating the obvious. ↩
-
I’ve moved to Excel and I have to say I find it cumbersome to use, compared to OpenOffice and LibreOffice. ↩
-
With DB2 Version 10 much of this is zIIP-eligible, and even more in Version 11. ↩
-
Hopefully this one causes a decrease. ↩
-
This one could go either way – with faster processors, or with multiprocessor effects. ↩
