(Originally posted 2018-12-11.)
I seem to spend a lot of time working with DB2 DDF, and it’s no wonder: Many modern applications accessing DB2 are built using it, whether through JDBC 1 or some other connective software.
This post is a by-product of a serious customer situation with DDF Performance, which I don’t intend to go into. As I say, it’s a byproduct, not the main event.
Before I continue, I have a small correction to make, which is highly relevant to this post: In DB2 DDF Transaction Rates Without Tears I labeled the authorisation unit of work as an SRB. In fact it’s a TCB.
A Brief Recap
SQL processing via DDF is done under an Enclave SRB. But before it starts, and at thread termination, code is run under a non-Enclave TCB. I’ve bolded these terms as they’re important for the discussion. In DB2 DDF Transaction Rates Without Tears I talked about classifying these enclaves, using WLM. This post, however, isn’t about that. I’m more interested in the non-Enclave TCB CPU time.
And, throughout this post, I’m referring specifically to the DB2 DIST address space. Hence the use of address space instrumentation.
zIIP Eligibility
We’ll return to this later in this post but it’s worthwhile talking about zIIP eligibility now.
It’s only the enclave portion of CPU that has any zIIP eligibility. The non-enclave CPU portion has no zIIP eligibility.
In this post, and with the examples I’m using, there is no zIIP-on-GCP. That simplifies things – and happens to be the truth in these cases.
CPU Numbers
To be able to continue this discussion we need to talk about CPU time. So let’s do so. Our source will be SMF 30 Interval records (subtypes 2 and 3). Specifically:
- SMF30CPT is the Preemptible Class CPU
- SMF30ENC is Independent Enclave CPU
- SMF30CPS is Non-Preemptible CPU (SRB)
- SMF30_ENCLAVE_TIME_ON_ZIIP – Independent Enclave CPU on zIIP
- SMF30_TIME_ON_ZIIP – CPU on zIIP
This, I’m sure you’ll recognise, is quite a sophisticated set of numbers. But it’s only a subset of those in SMF 30. And, for less exotic address spaces, most of this sophistication isn’t needed. “Less exotic” includes batch jobs.
A Tale Of Two Customers
The “meat” of this blog post is how these numbers play out in practice. The following graph incorporates data from two customers I know well, each with multiple DB2 datasharing groups.
I’ve summarised the numbers over an eight hour shift. I’m primarily looking at two things:
- Percentage zIIP eligibility
- Distribution of CPU between the various types of work units
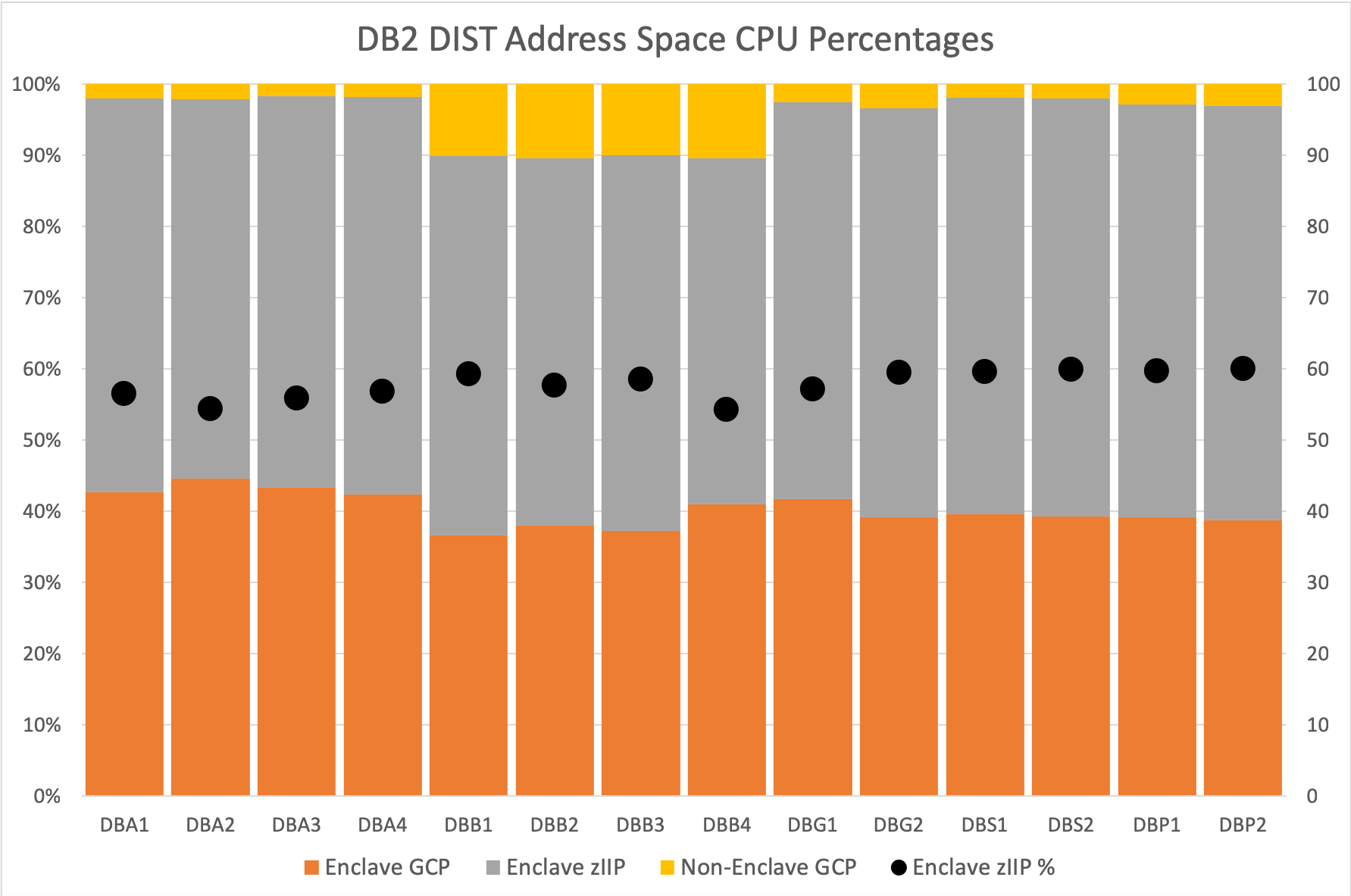
These customers show quite diverse DDF behaviours; Each datasharing group is quite different, even within an individual customer.
I’ve, as you might expect and hope, obfuscated the names somewhat:
- Client A has two datasharing groups: DBAx and DBBx – being the members
- Client B has three datasharing groups: DBGx, DBSx, and DBPx
I’m showing percentages of the total, rather than absolute values. I think this tells the story better.
zIIP Eligibility
In both these customers, and they weren’t particularly chosen for this, the processors are z13 7xx models – so the zIIP speed is the same as the GCP speed. (This post isn’t about normalisation, or it’d be a good deal longer.)
It’s only the enclave portion of the CPU that has any eligibility. And for these zIIP eligibility is on and individual thread basis: A thread is either eligible or it isn’t.
The line in the graph – or rather the round blobs – shows zIIP eligibility hovering just under 60% – across all the DB2 subsystems across both customers. (One of the things I like to do – in my SMF 101 DDF Analysis Code – is to count the records with no zIIP eligibility.)
As the folklore suggests you should get around 60% this all seems normal.
CPU Distribution
This is the bit that got me going in the first place: I’ve always asserted that the non-enclave TCB time should be small.2
But in the case of one of these datasharing groups that wasn’t the case: Looking at the DBBx members in the graph you can see that their non-enclave TCB time on a GCP is around 10% of their entire CPU.
You could argue that this datasharing group is out of line with the others. I don’t want to make that argument; There’s some variability between members and datasharing groups as a whole.
An obvious question is: “What causes the variation?”. Most of the code that’s run on the TCB before the transaction hops on the enclave SRB is authorisation.
One clue is that DBAx members are long running threads that persist across many DB2 commits 3. DBBx members have shorter-running threads that don’t. So we might expect the latter to go through authorisation more often. It could also be that each pass through authorisation is more expensive. Further on that point, it could be that each pass through authorisation is more expensive relative to the SQL processing.
At this point I’m speculating. But I would want to know why one set of subsystems behaved differently to others.
What Do I Conclude?
First, not all DDF environments behave the same, even within a customer.
Second, SMF 30 is a valuable tool for understanding something about a DB2 subsystem’s DDF work. It’s worth profiling in the way I have here, along with what I described in DB2 DDF Transaction Rates Without Tears.
And there might be value in drilling in to the data, below the shift level. Perhaps next time I have a DDF situation I will.
And, out of the corner of my eye, I see a customer with significantly less than 60% of Enclave CPU being zIIP-eligible. Interesting…
As Robert Catterall points out in this blog post non-native stored procedures could cause this. I’m just wondering where the CPU gets clocked back to – in SMF 30 terms.

One thought on “DDF TCB Revisited”