(Originally posted 2012-03-08.)
Now with free map :-), this is the concluding part of a four part series on batch parallelisation, with especial focus on cloning.
In previous parts I discussed:
This part wraps up with thoughts on implementation. I’m going to break it down into:
- Analysis
- Making Changes
- Monitoring
While there probably are iterations of this, this is the essential 1-2-3 sequence within the cycle.
I’m repeating the example from Part 3, partly because I raised some issues in relation to this diagram I want to cover here:
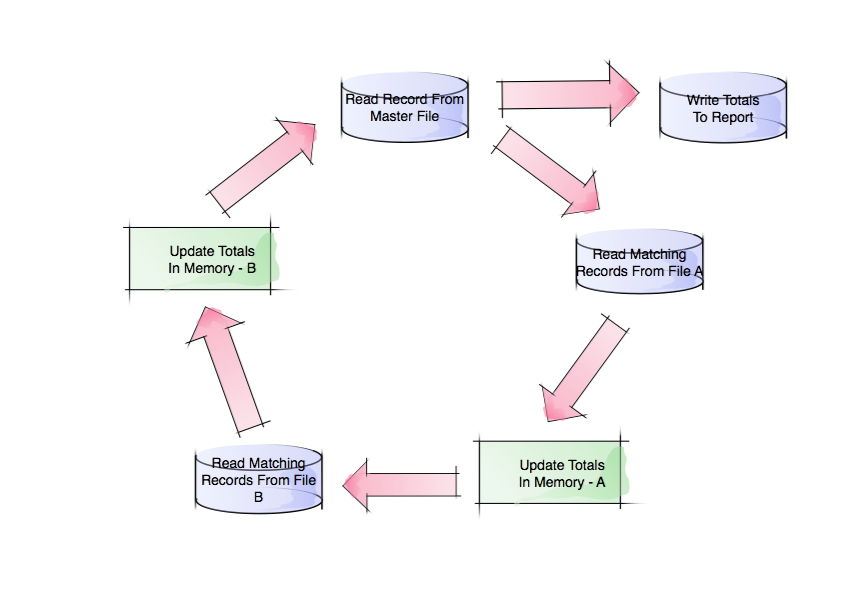
Analysis
Finding good places to use cloning is the same as finding good jobs to tune, with one further consideration: Because cloning is riskier and more difficult to do you’d want to be sure it was the right tuning action.
If you can find an easier tuning action that makes the batch speed up enough for now, while being scalable for the future, do it in preference to cloning. If you’re "future proofing" an application to the extent where other tuning methods aren’t going to do enough then consider cloning.
Modifying this advice only slightly, consider that you might be able to postpone cloning for a year or two. In this case keep a list of jobs that might need to be cloned eventually.
A couple of examples of where cloning might be indicated are:
- Single-task high CPU burning steps
- Database I/O intensive steps
Of course, feasibility of cloning comes into it. I’d view this as the last stage in the analysis process. As I like to pun: "the last thing I’m going to do is ask you to change your program code". While there may be some cases where application1program change can be avoided, the majority of cases will require code surgery. The cases where surgery isn’t required are where the data can be partitioned and the existing program operates just fine on a subset of the data.
Making Changes
(This whole post is "Implementation" but this is the bit where the real implementation happens.)
Let’s divide this into six pieces, with reference to the diagram above:
- Splitting the transaction file
- Changing the program to expect a subset of the data
- Merging the results
- Refactoring JCL
- Changing the Schedule
- Reducing data contention
Splitting
As noted in Part 3, the transaction file drives the loop: Each cycle round it is triggered by reading a single record from this file. Suppose we wanted to clone "4-up" i.e. to create four identical parallel jobs. There are a number of ways we could do this:
- Use a "card dealer" like DFSORT’s OUTFIL SPLIT to deal four hands.
- "Chunk" the file, perhaps with DFSORT’s OUTFIL with STARTREC and ENDREC.
- Split based on criteria, You could use DFSORT OUTFIL with INCLUDE= or OMIT=. Or else you could use an application program.
There are considerations with all of these:
- The card dealer (1) ensures (practically) equal numbers of records in each transaction file, but there is no sense of logical portitioning. So it could provide balance but at the expense of cross-clone contention.
- Neither 2 nor 3 guarantee balance across the clones. For example, Method 3 might divide records into those for North, East, South and West regions – where that division could be decidedly unequal.
- Method 3 might not be scalable to 8-up or 16-up, simply based on the difficulty of finding 8-way or 16-way split criteria.
- Method 2 could allow some clones of the original application program to start earlier than others. In some cases this is a good thing, in others a problem.
- Method 2 would need occasional adjustment to rebalance.
- Method 3 implies non-trivial application coding to effect the split but provides the best chance of minimising contention between streams. (One neat coding shortcut if you’re using DFSORT to do the split is OUTFIL SAVE – which provides a "non of the above" bucket.) Whether you use DFSORT or a home-grown split program depends on the precise split logic – but DFSORT is much simpler and scales slightly more easily to e.g. 8-way and 16-way.
Changing Programs To Expect Subsets Of The Data
In our example the original program processed all the data. It could make the "I am the Alpha and the Omega" assumption. If we split the transaction file we forego this. The most obvious result is that any report the program would have written needs to be rethought: We probably will only be able to write out a file that feeds into a new report writer (Which we’ll talk about below.)
Merging
Batch steps produce, amongst other things, output transaction files and reports. For the sake of (relative) brevity let’s concentrate on these two:
Output Transaction Files
Somehow we need to merge these files (though an actual sort is unlikely). It’s important to know what the sensitivity is and cater for it.
Reports
Reports usually require some calculations, extractions to form headings, and so on. Sometimes a simple merge of the report output from the cloned program is enough. My expectation, however, is that serious reworking is usually required. Totalling and averaging would be typical examples of where it gets complex (but not impossible).
I would remove the reporting from the original program and think about where it fits best in the merge. There are advantages to separating the data merge from the "presentation": If today the report is a flat file (14032 format?) you could enhance the report to also3 produce a PDF or HTML version. That might be a nice "modernisation".
Refactoring the JCL
JCL Management is not my forte but it’s obvious to me it’s worth examining the JCL for any job that’s going to be cloned to see how it can best be managed.
It might not be feasible to keep a single piece of JCL in Production libraries for the schedule to submit as multiple parallel jobs. If you can then parameterisation is the way to go. For instance it wouldn’t be helpful to have the job name hardcoded in the JCL. Similarly data set names which differ only by the stream number need care, as would control cards you pass into a program.
Changing The Schedule
You have to change the schedule to accept new job names – for the clones of existing jobs – , insert new jobs (for splitting, merging and reporting), and wire this all up with a reworked set of dependencies.
There are decisions to make, such as whether (in TWS terms) each stream should be its own Application, and what the dependencies should be. For instance, do you keep the streams in lockstep?
One of the key things is planning for recovery: Whereas, in our example, it was all one job step you now have three (or maybe) four phases of execution. Where do you recover from?
Reducing Data Contention
In our example, File A and File B were originally each read by the original application program. If they were keyed VSAM, for example, buffering might’ve been highly effective – particularly with VSAM LSR (Local Shared Resources) buffering. Four clones reading these two data sets will have to do more physical I/O. In the VSAM LSR case some hefty buffer pools could help reduce the contention going 4-up might introduce. In a database manager like DB2 things ought to be better: Data is buffered for the common good.
Dare I mention Hiperbatch? 🙂 For the smallish4 Sequential or VSAM NSR (Non-Shared Resources) case this might work well – but it would be a very uncommon approach.
As I hinted above, one of the things that might condition how you split the transaction file is what effect it would have on data contention. If you found a split regime where all the data the clones processed was split the contention could be very low.
If you got to the point where the split regime was "universal" or at least widespread enough some of the contention (and indeed Merging) issues would disappear completely.
Tape is particularly fraught: You can’t have two jobs read the same tape data set at the same time. I’ll indulge myself by mentioning BatchPipes/MVS here 🙂 as it provides a potential solution: A "tape reader" job (probably DFSORT COPY OUTFIL) copying the data to the clones through pipes.
However you do it, the point is you have to manage the contention you could introduce with cloning.
Monitoring
Monitoring isn’t terribly different from any other batch monitoring. You have the usual tools, including:
- Scheduler-based monitoring tools – for how the clones are progressing against the planned schedule.
- SMF – for timings, etc.
- Logs
If you can develop a sensible naming convention for jobs and applications your tools might be easier to use.
One other thing: You need to be able to demonstrate that the application still functions correctly. This is not a new concept, of course, but application testing is going to be challenged by the level of change being introduced.
This concludes the four-part series. If you’ve read all four all the way through thanks for your persistence! The purpose in each was to spur thought, rather then be a complete treatise. My next task is to turn this into a presentation – as the need has arisen to do so. One final thought: If this long (but necessarily very sketchy) post has put you off please re-read Part 1 as I talk there about why this could be necessary.
1 This usage of "application program" most centrally refers to programs written in programming languages such as COBOL. It could also refer to things like DFSORT invocations. The point is these are difficult things to understand and to change.
2 You do know about DFSORT’s REMOVECC, don’t you? It tells DFSORT to remove ANSI control characters – such as page breaks. When separating data preparation from presentation you may well find it useful.
3 I bolded "also" here because the original report probably has a consumer – whether human or not – who’d get upset if it didn’t continue to be produced but might like a more modern format. And if it doesn’t… 🙂
4 While technically still supported, Hiperbatch has functional limitations, such as not being supported for Extended Format data sets (whether Sequential or VSAM). Further, the only way to process Sequential data with Hiperbatch is QSAM. (For DFSORT you’d have to write an appropriate exit – E15, E32 or E35 – to read or write the data set.)

2 thoughts on “I Said “Parallelise” Not “Paralyse” Part 4 – Implementation”