(Originally posted 2012-03-04.)
Part 1 and Part 2 were, in my opinion a little abstract. But I think they needed to be:
- They set the scene for why parallelising your batch can be important.
- They gave some vocabulary and semantics to help structure our thoughts.
Now we need to go a little deeper.
Let’s start with how to think about the problem of making a job or set of jobs more parallel.
Hetereogeneous Parallelism
Here the trick is to remove dependencies – and that’s where most of the issues are.
I covered a lot of this in Batch Architecture, Part Two.
Homogeneous Parallelism (Cloning)
This is where it can get really tricky. And that’s why the bulk of this post is about the homogeneous case. (Some of the following will also have relevance to the heterogeneous case.)
There are a number of issues to work through when cloning jobs. Here are some of them:
- Converting the serial bulk processing model to something more parallel.
- Handling inter-clone cross-talk
- Resource provisioning
- Scheduling
Parallelising The Bulk Processing Model
The reasons for using batch include the advantage of using a “bulk processing model”: Doing the same thing to lots of data in one job is much more efficient than breaking it up into a huge number of one-datum transactions. But, just because it’s more efficient to process 10 million records in a single batch job doesn’t mean it’s much more efficient than doing it in 10 1 million record jobs.
The trick with cloning is to find a way of breaking up an (e.g.) 10 million record job into ten parallel 1 million record jobs.
Consider the following diagram1:
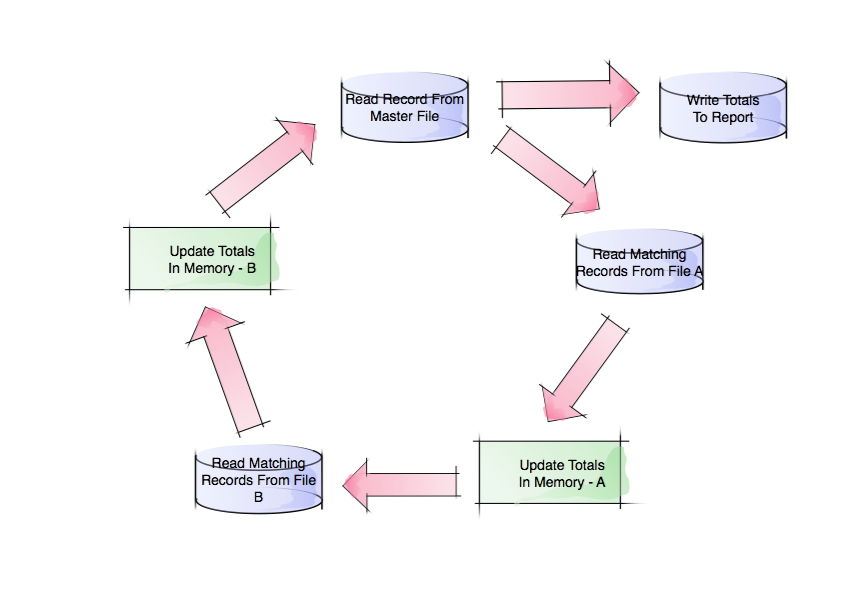
A lot of bulk processing looks like this. The salient features are:
Reading a Master file, one record at a time.
This could be a sequential file, a concatenation of these, a VSAM file, rows returned by a DB2 query, or any one of a number of other similar “files”. The point is it’s a large number of records or rows – perhaps the 10 million mentioned above. And any serious attempt to parallelise this job is going to have to split this file.
FIle A is read to provide detail.
Hopefully this is a keyed (direct and buffer able) read. You don’t want to have to read the whole file to find a match to the record from the Master file.
- Likewise File B.
- The detail that is being filled in – in this case totals – is held in memory by the program.
- When the Master file has been completely processed a report is written – using the summarisation information in memory.
I find this notion of a circuit, driven by a Master file, useful. If you find you can’t draw it that tells you something in itself. I’m sure it’s not the only bulk processing pattern, but it’s a very common one.2
(It would be difficult to attach timings to the activities in the loop. A reasonable stab could be made, under some circumstances, at the data set accesses’ proportions of the overall run time using SMF 42 Subtype 6 records.)3
This is only an example but it illustrates some issues that cloning needs to resolve:
- The Master file needs to somehow be split into 10.
- The ten sub-reports need to be reworked to produce a coherent and correct final report.
We could talk about resolutions of these – and I probably will in Part 4 – but the important thing is to acknowledge these are issues that have to be addressed.
Resources
If you’re going to run more jobs in parallel you could easily “spike up” resource usage, most notably CPU consumption. Memory use might increase also, though some usage patterns (such as DB2) tend to have a noticeable memory impact. I/O bandwidth and initiators are two more things to think about. In the I/O case it could be seen as a case of this. In any case, we know how to monitor resource usage, don’t we?
Handling Inter-Clone Cross Talk
While logically it might be easy to clone a job, things like locking can make it really difficult.
For example, in (a modified version of) the case above, File A and File B might be updated. These updates might be one per record in the Master file, or just at the end. In either case cloning would introduce some locking issues. It might be possible to resolve these issues – perhaps through partitioning.
Even in the unmodified version clones reading from File A and File B might create I/O bottlenecks. In the DB2 case you’d hope this would have a happy ending.
Scheduling
If you’re going to run multiple copies of a job in parallel you need to adjust the schedule.
There are design decisions like whether you keep clones in lockstep:
Consider this example: Suppose you have a pair of cloned streams – consisting of A0, B0 and C0 in Stream 0 and A1, B1 and C1 in Stream 1. Each Bn logically follows its corresponding An and each Cn follows the corresponding Bn, based on data flows.
- If you release B0 and B1 only when both An jobs have completed it’s more controlled but probably takes longer.
- If you release each Bn when the corresponding An completes its’ less controlled but probably takes less time.
The term “Recovery Boundary” is probably useful here as recovering from job failures is the thing that makes the complexity introduced by cloning really matter.
I advocate cloning in powers of two: 2-up then 4-up then 8-up, and so on. A modification to this is 3-up, then 6-up, then 12-up – which has a fairly obvious appeal, when you consider typical data sets.
Automating cloning is a useful aim, whether you want to “dynamically” partition the work or just want to be able to move from, say, 4 streams to 8 without too much trouble. I put the word “dynamically” in quotes as realistically the latest you could decide on the number of clone streams is just before you kick them off. In reality it’s probably much earlier than that.
So you need to solve the problem of how you might do this: The first step would be to decide what’s realistic. The second would be to decide what’s needed.
In this post I’ve highlighted some of the issues – mainly for cloning. They’re not terribly different from this you’d encounter if you were pursuing homogeneous parallelism (which you may also need to do). Part 4 will round out the series with some thoughts on implementation.
1 Made with Diagrammix for Mac. I like this particular style, untidy thought it may be. A nice demo is here.
2 There probably are formal diagrams of this type, probably with the letters “UML” attached to them. I don’t claim to be the kind of person who would use one. I just think teasing out the circuit like this is helpful for cloning. It’s the circuit itself I’m attached to.
3 Quite apart from the incompleteness of this approach there are issues with overlap between the data sets (and with CPU). A discussion of double buffering, access methods and I/O scheduling is well beyond the scope of this post.

2 thoughts on “I Said “Parallelise” Not “Paralyse” Part 3 – Issues”