(Originally posted 2012-12-02.)
Or should that be “Subjective Data And The Bad Mood”? 🙂
A good friend of mine says that when dispensing advice one shouldn’t use “may” or “might”, but that one should be more definite.
I’ve probably said this before: When I say or write “may” or “might” I’m deploying the subjunctive mood for what I hope aren’t “weasel words” reasons. My claim would be the subjunctive mood reflects some underlying subtlety like genuine reasons for doubt, and that I’d be forthright in standing behind this more nuanced position.
(I do sometimes catch myself saying “may” when I mean “might”, but I think we all do that.)
Now, to come to(wards) the point, I’ve been saying for a while now that “data provenance” is important.
So I see a field in a record which is acting bizarrely (as happened to me this week)…
- Do I conclude the field is broken?
- Do I conclude it’s telling the truth?
- Do I conclude it’s telling one version of the truth?
I think the sensible thing to do, rather than leaping to any conclusion, is to seek corroboration. But also situational context.
This latter point is actually quite important and one us technical people tend to forget… So what if MSTJCL00’s working set appears to be 2GB on every LPAR the customer has? (And this was the case this week.) The “so what” on this one is the obvious economic cost but also the sneaking suspicion that some other nasty effects are occurring. (Perhaps cruelly it might be worth noting the customer should’ve spotted this – if it’s a true phenomenon.)
I’ll also note that in my – nowadays wide and varied – experience of customer systems I’ve never seen MSTJCL00 be more than a few tens of megabytes. Indeed another customer’s data that I’m currently reviewing shows this norm in action.
I glossed over corroboration back there. It turns out the customer is also seeing the phenomenon – now they’re looking for it (I think using RMF Monitor III) – and will be pursuing it as a potential defect. Where that takes us I don’t know yet, it being out of my sphere of understanding.
But you can see that for me to barge into the customer and tell them that they’d better fix this usage of memory, without a hint of doubt, would not be the right approach. Working with them to establish the truth and its relevance is much better. So phrasing like “it looks a lot like you’ve got a problem worth worrying about with MSTJCL00’s use of memory” is better.
By the way in this case I suspect MSTJCL00 (Address Space 1) is an anchor for the storage and it may well be some other user of 64-bit Common that’s the real big user.
In case you think this might be bad data or at least an isolated bad data point look at the following graph:
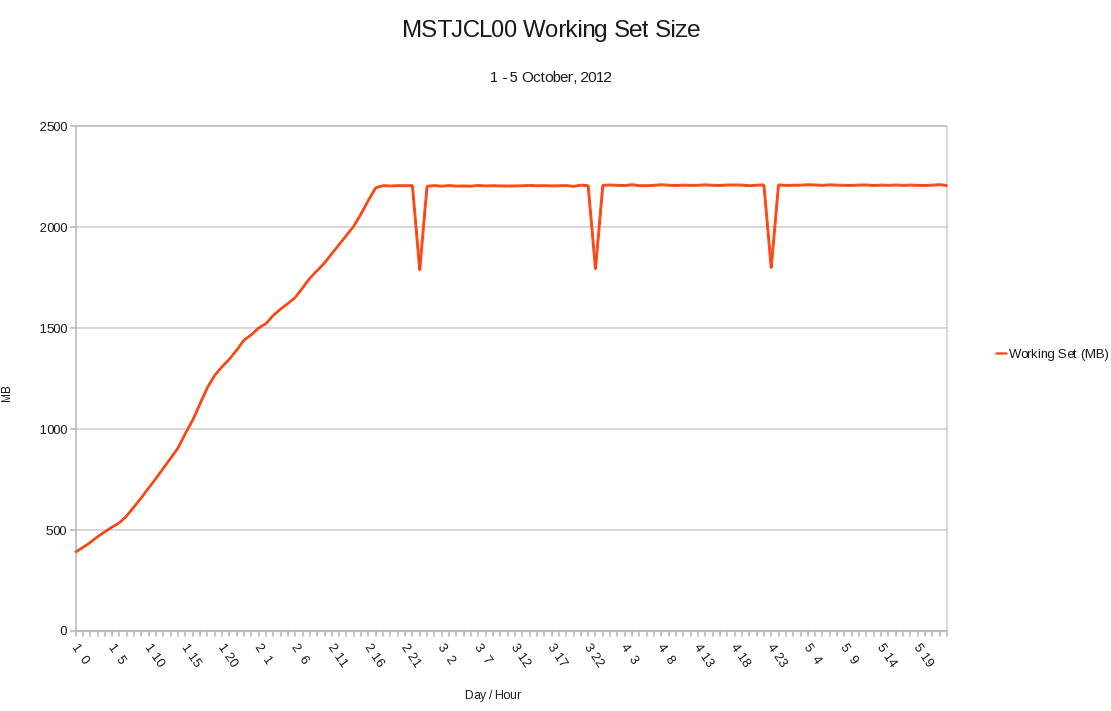
The days and hours are along the bottom and the system was IPL’ed the day before.
There is something funny about the 11PM hour on each day (which might give a clue) but otherwise the picture is reasonably clear:
- The working set rises from a “normal” value just after IPL until it reaches a steady state.
- If this is a memory leak then something’s having to “bail out” to create the levelling off we see.
- As the final usage is more than 2GB this is either a number of 31-bit address spaces and/or dataspaces, or else it’s 64-bit. Personally I suspect the latter and that this is a 2GB large memory object filling up. But what?
So one of the points here is the value of a time-driven view.
Now for something approaching a “payload” for this blog post:
We have to be careful of the provenance of any data we use. And a very good book on the subject I’ve been reading is Bad Data Handbook. Whether you’re a data scientist (and I think very few of those would be following this blog) or a performance specialist it’s a very worthwhile read, being a collection of papers from many authorities on the subject. You won’t find anything specific to mainframe performance in it but the more general lessons are readily applicable. In general performance people need to take on board some of the data science lessons and this is a good primer.
(I bought my copy as a digital download: It seems O’Reilly have frequent 50% off deals and I took advantage of the recent one. There might be another one along soon.)
See what I did just there: I used the subjunctive mood (“might”) to alert you to the possibility. I think that was useful. 🙂
The point of this post has been threefold: To urge the correct use of “might” (and “may”), to mention this MSTJCL00 observation at a customer, and to mention the Bad Data Handbook. Comments on all of these are, of course, welcome.

One thought on “Bad Data And The Subjunctive Mood”