(Originally posted 2012-11-24.)
I seem to be obsessed with finding patterns in data, don’t I? And, to my mind, I’m insufficiently obsessed to bring it all to a thunderous conclusion.
Pardon the self-flagellation 🙂 here: This stuff is technically difficult. But just yesterday I think I made a breakthrough. I think it’s worth sharing it with you. But first some motivation and some prerequisite knowledge.
Motivation
In one of my current studies I encountered a WLM service class with over 100 IMS Message-Processing Regions (MPR’s), a sea of address space names that all seemed to start with “IM” and had a “T” as the fourth character. I wanted to do two things:
- See how well this pattern fitted (and any others I thought I saw).
- Extract any varying portions.
As you’ll see with Regular Expressions I could do both.
Regular Expressions
Regular expressions (in this post referred to as "Regexps" though often seen as "Regexes" or "Regex’s") neatly (but geekishly) solve the problem of a general search and matching language).
Regexps are extremely powerful and reasonably well understood in the Unix / Linux / Web world. We don’t really know them in the z/OS world but we can certainly use them. Tools like sed, awk and grep all use Regexps. In my case I’m using the PHP built-in prey_match() function.
Consider the following regular expression: ^IM(.)T(.+)$.
It looks complicated, but let’s dissect it:

Believe me you soon get used to the above set of pretty standard pieces of RegEx.
This particular Regexp wasn’t chosen at random, or particularly to show off features. It’s actually the first one I used on real live jobnames – as I thought I saw a pattern.
Capturing groups need a little explanation – as they’re a very useful and highly relevant feature of Regexps. They have two main functions:
- Allowing you to extract the varying portions of the string being matched. This, you’ll recall, I wanted.
- Through the use of back references to refer to a varying match early in the Regexp in a later portion of the Regexp. For example, “\1” refers to the first capturing group. (I actually didn’t need this but it’s possible I might in some other set of data.)
I replaced the second capturing group – “(.+)” – with one that more tightly defined the match: “(\d+)” matches any number of numeric digits. The number of matches stayed the same, demonstrating that all the jobs had a trailing numeric identifier. (I’d suspected this but wasn’t keen on wasting my time checking it when a well-crafted Regexp could do it for me.)
So, I’ve shown you some of the power of Regexps. And they’re not too bad to work with once you’ve got used to them.
My Prototype
Bear in mind this is a prototype that’s already yielded results: I’m confirming patterns, counting matches and extracting variable portions of job names.
I wrote some PHP code, using the preg_match() built-in function to do the Regexp work. This code reads a file containing the results of a query against my performance database, each line starting with the SMFID and the job name. It also puts up an HTML form (the reason this is PHP) which allows me to enter up to five Regexps. These Regexps are all applied to each job name and a line printed about the job’s matching, including the fragments yielded by the two capturing groups.
A count of matches for each Regexp is printed at the bottom, together with the number of job names that failed to match any of the Regexps.
In fact with five Regexps only one job name failed to match. These five Regexps are disjoint in that none are refinements of any of the others. If I put them on a pie chart it would look something like this:
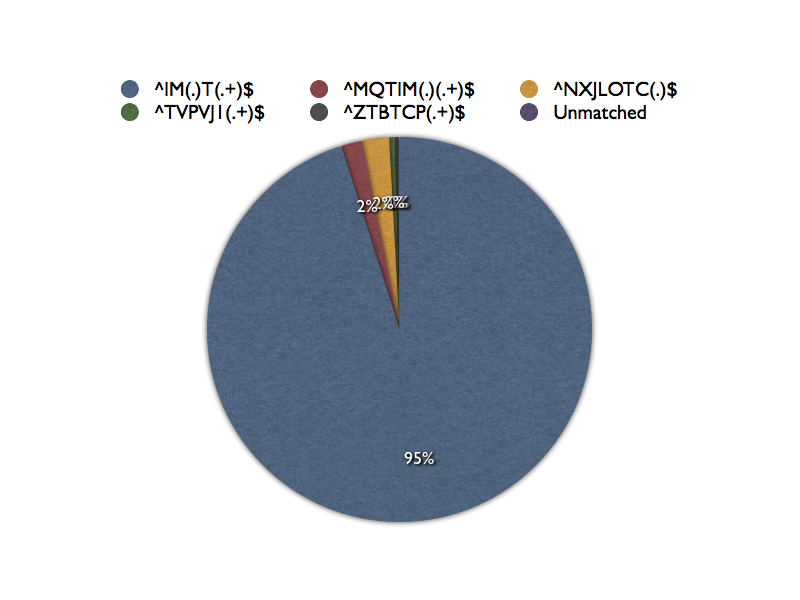
I don’t suppose I’m going to present it to the customer with labels such as these. 🙂
Conclusion
This is just the start of something, and there are lots of ways to go on it. But it’s immediately useful.
I wrote the PHP code in such a way I could easily allow for more RegExps.
I could work on the presentation a lot. I could, for example, do some analysis of the varying portions of the job names.
I could apply it to just about any character string, from an data. So, for example, data set names, volsers, SMFIDs are just a few possibilities. And I could use it to analyse multiple (space-delimited) fields at once: An interesting one which actually would use back references is checking whether a portion of the SMFID appeared in the jobname (or if the SMFID appeared in a data set name).
What I think is a lot further away is automatically generating the Regexps. I’ve made attempts at this before but I think typing in my own Regexps is quite good enough.
You’ll recognise there are common building blocks in the Regexp I’ve dissected:
- “^” and “$” as anchors.
- “(.)”, “(.+)” and “(\d+)” as capturing groups.
- “/1” etc as back references.
- Literal character strings.
Some of these could become buttons and some entry fields. So I could simplify the creation of Regexps a little. (If it’s just for me I don’t think I’ll bother.)
So lots of possibilities. I’m just very pleased it worked. And I think many of you might find it a useful technique, too: Throwing a battery of Regexps at e.g. job names.

2 thoughts on “Towards A Pattern Explorer – Jobname Analysis”