(Originally posted 2014-11-29.)
Here’s an interesting case that illustrates the effect of distance between a z/OS image and a Coupling Facility structure.
I don’t think this will embarrass the customer; It’s not untypical of what I see. If anything I’m the one that should be slightly embarrassed, as you’ll see…
A customer has two machines, 3 kilometers apart, with an ICF in each machine and Parallel Sysplex members in each machine. There is one major (head and shoulders above the rest) structure: IRRXCF_P001 (with a backup IRRXCF_B001 in the other ICF).
The vast majority of the traffic to this structure is from a system on the “remote” machine (the one 3km distant from the ICF).
At this point I’ll admit I’d not paid much attention to IRRXCF_Pnnn and IRRXCF_Bnnn structures in the past – largely because traffic to them is typically lower than other structures such as DB2 LOCK1 and ISGLOCK (GRS Star). I hadn’t even twigged that this cache structure was accessed via requests that were initially Synchronous. (And that’s the tiny bit of embarrassment I’ll admit to.)
RACF IRRXCF_* Structures
Let me share some of what the z/OS Security Server RACF System Programmer’s Guide says:
To use RACF data sharing you need one cache structure for each data set specified in your RACF data set name table (ICHRNDST). For example, if you have one primary data set and one backup data set, you need to define two cache structures.
The format of RACF cache structure names is IRRXCF00_tnnn where:
- t is “P” for primary or “B” for backup
- nnn is the relative position of the data set in the data set name table (a decimal number, 001-090)
So the gist of this is that it’s a cache for RACF requests and it’s accessed Synchronously – at least in theory.
So what does “accessed Synchronously” actually mean?
RACF issues requests to XES, which is the component of z/OS that actually communicates with Coupling Facility structures. XES can decide to convert Synchronous requests to Asynchronous, heuristically.1 So in this case it means RACF requested Synchronous; XES might have converted to Async, depending on sampled service times.
A Case In Point
Now to the example:
Three systems (SYSA, SYSC and SYSD) are on the footprint 3km away from the structure. SYSB is on the same footprint as the structure.
Let’s first examine the traffic rate:

As you can see the vast majority of the traffic is from SYSC and almost all the traffic is Async (and RMF doesn’t know if RACF issues the requests Sync (and they were converted to Async) or if RACF issued them Async). The fact all three remote systems are more red than blue, while the local one (SYSB) is all blue, suggests RACF issues them Sync (as if we didn’t know).
Now let’s look at the response times:
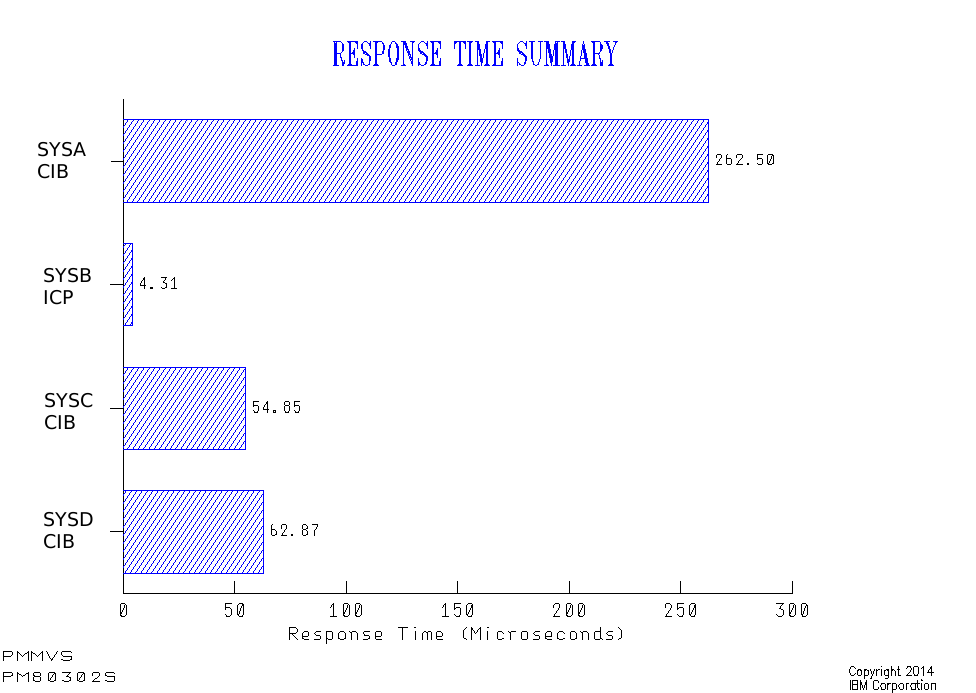
Here the local system (SYSB) using IC Peer (ICP) links shows a very nice response time under 5µs.
The remote systems (using Infiniband (CIB) links) show response times between 55 and 270µs.
A reasonable question to ask is “how come SYSC has so much better response times than SYSA and SYSD as they’re on the same footprint?”
You might think it’s because it has some kind of Practice Effect; You drive a higher request rate and the service time improves (which XCF’s Coupling Facility structures often appear to exhibit).
But here’s a graph – just for SYSC – which disproves this:
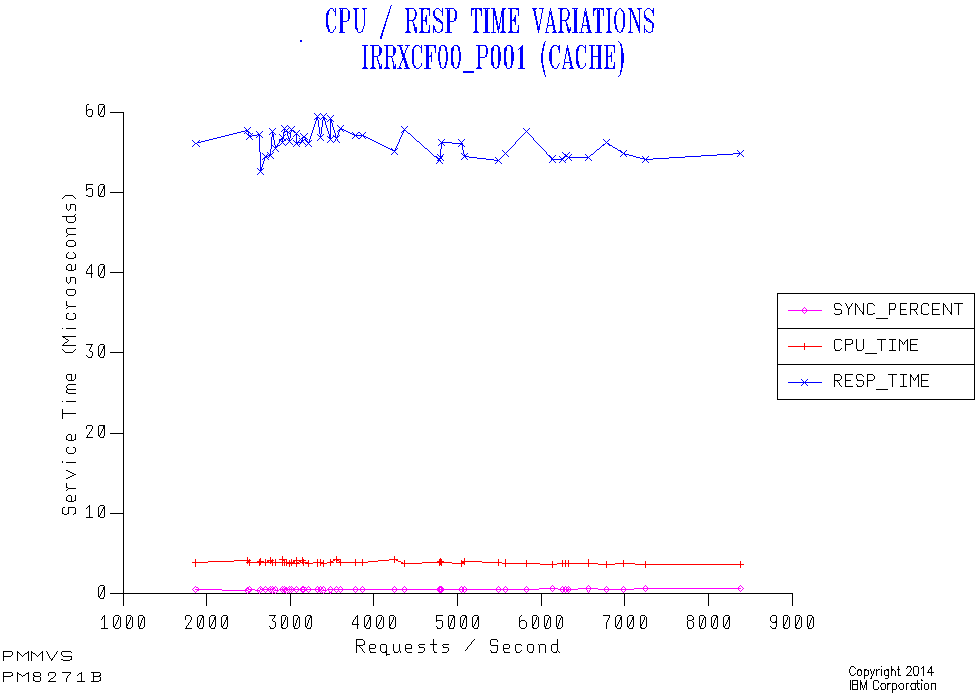
I’ve sequenced 30-minute data points not by time of day but by request rate. Here are the highlights:
The response time stays level at 50-60&us. regardless of the request rate. So it’s not a Practice Effect.
The percent of requests that are Sync stays very low – so conversion is almost always happening. (At least it’s consistent.)
The Coupling Facility CPU per request (not Coupled (z/OS) CPU) is around 5&percent. of the response time; The rest is the effect of going Async as well as the link time.
Now SYSA has a much lower LPAR weight than SYSD, which in turn has a lower LPAR weight than SYSC. The response times are the opposite: SYSC lowest, then SYSD, then SYSA.
So we have (negative) correlation. But what about causation?
Well, I’ve seen this before:
When a request is Async (whether converted or not) the request completes by the caller being tapped on the shoulder. In a PR/SM environment this can’t happen until the coupled (z/OS) LPAR’s logical engine is dispatched on a physical engine. If the weight for the LPAR (or vertically for the engine in the Hiperdispatch case) is low it might take a while for the logical to be dispatched on a physical.
The consequence is that lower-weighted LPARs get worse response times for Async because of the time taken to deliver the “completion” signal.
A Happy Ending
My advice to the customer was to move the IRRXCF_P001 structure to the Coupling Facility on the same footprint as the busiest LPAR (SYSC).
They did this and the response time dropped to 4µs, with the vast majority of the requests now being Sync.
This is an unusual case in that normally one LPAR doesn’t dominate the traffic to a structure. So the choice of where to put the structure was unusually easy.
I would add two things related to the applications on SYSC:
They are IMS and I don’t know enough about IMS Security to know whether it is possible to tune down the SAF requests to reduce the Coupling Facility request rate, without compromising security.
There is no direct correlation between IRRXCF_P001 service time and IMS transaction response times. Such is often the way.
But this has been an interesting and instructive case to work through. And you could consider this blog post penance for mistakenly thinking RACF Coupling Facility requests were always Async. 🙂
In a similar vein you might like:
zBC12 As A Standalone Coupling Facility? from earlier this year
Coupling Facility Memory where the numbers are made up, unlike in this case.
1 But XES can’t convert Async requests to Sync.

3 thoughts on “The Effect Of CF Structure Distance”