(Originally posted 2016-08-21.)
The title of this post is a Physics reference but this is not about Physics.1
A customer asked me the question “why am I not getting balanced CPU Utilisation between the various machines”? I’m responding without data at this stage so I’m going to be even more “hand wavy” than usual – both in the long call I had with them and this post.
So, let’s take it in stages…
Why Would You Want Balance?
I think it’s important to put this in context: You’re probably never going to achieve perfect balance, so the real world can’t be an automatic fail.
However, there are real world outcomes from imbalance. In the following diagram the impact – however you measure it – is much greater at higher load.
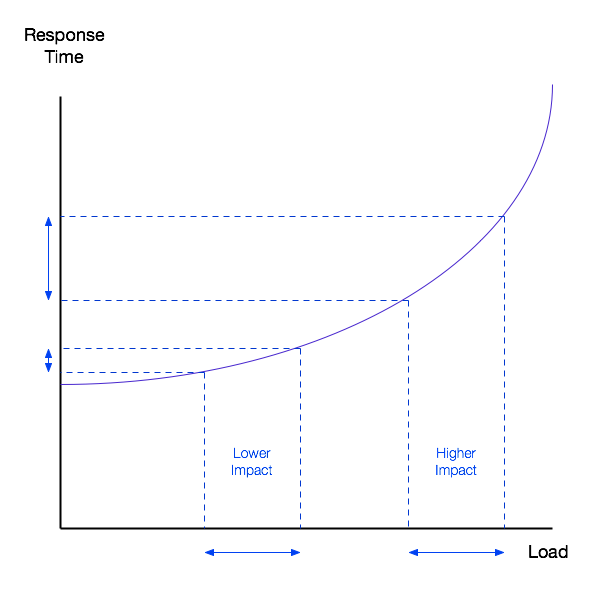
And you might measure it in terms of things like:
- CPU per transaction
- Transaction response time – the example given in the graph
- Batch runtime
- Virtual Storage occupancy
So there can be an impact and that should help you judge what is trivial imbalance and what is substantial.
Consider the following two cases:
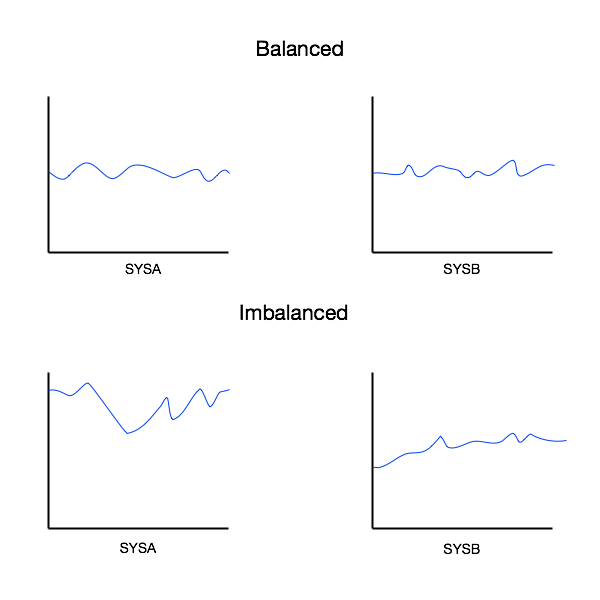
Obviously in the former case the imbalance – taken as a whole – is not as severe as in the latter case. Momentarily, however, it could be significant 2.
There are other considerations:
For example, suppose you have a System Design Point of say 90%. That’s where no system should exceed that level of utilisation. Then significant imbalance (or skew) would cause other systems to have to have a lower maximum utilisation. So upgrades might have to happen sooner.
Where Does Imbalance Come From?
I would divide the causes into two:
- Long-term structural asymmetry
- Short-term routing decisions
Structural Asymmetry
When I look at customers’ mainframe estates I often see symmetric (at a high level) configurations. For example, the “twin machine” architectural pattern is commonplace.
If I dig a little deeper I might see sysplexes spread across these two machines, but additional LPARs on either side that break symmetry.
I might also see the two machines aren’t identical, hardware-wise. For example, one might be a z13 and the other still a zEC12.
Even if the machines are similar enough, their connectivity might not be. For example:
- The primary disk controller might be in the same machine room as one machine, but distant from the other (because the latter is in a different machine room).
- Connectivity to an external coupling facility might be asymmetrical.
Take the case where a sysplex comprise four3 members, two to a machine. I’ve seen cases where these four members aren’t running quite the same workload, in architectural terms. Two examples I’ve seen:
- CICS regions might appear on two members with no analogues on the other two
- Distributed (DDF) DB2 work comes into 2 members of the sysplex but not the other two.
- Likewise asymmetric MQ connections.
Routing Decisions
Work gets routed on a continual basis. I think we can divide this neatly into two:
- Big globs such as Batch
- Smaller pieces of work, such as CICS, IMS and DDF transactions
In principle, big globs ought to be harder to balance than transactions, as should work with affinities. In practice I’ve found this to indeed be so as I’ve had quite a few questions about Batch imbalance.
There are two primary workload distribution systems:
- Round robin, like a card dealer
- Goal oriented, where quality of service influences placement
The former tends to even out the transaction rate, whether work is routed to the optimal place or is indeed CPU-wise balanced. But, statistically speaking, the chances of CPU balance are pretty reasonable.
The latter also has the potential for imbalance, because a better-performing server could well receive the bulk of the work. This imbalance could very well be OK as the aim is to run work well.
Imbalance in the “goal-oriented routing” case is especially a concern with a mixture of faster and slower systems, but this is really a case of Structural Asymmetry, as previously discussed.
How Can I Look At The Data?
The standard “problem-decomposition” approach applies but it’s worth rehearsing it:
- Machine- and LPAR-level configuration and CPU Utilisation from RMF SMF 70
- I/O Subsystem and Sysplex with various subtypes of SMF 74
- Workload-level with RMF SMF 72
- Address Space-level with SMF 30 Interval records
- Transaction level with SMF 101 (DB2), 110 (CICS), MQ (116), 120 (WAS)
All the above is pretty standard and I hope you can see how each of these sets of instrumentation can detect imbalance – whether transient or structural.
Conclusion
So all the above was “talking cure” thinking it through; I suspect actually seeing data would add a whole extra layer of insight and experience.
-
And no I didn’t know the Blake origin (according to this). ↩
-
And with something like “Sloshing” – which generally isn’t detectable at the RMF e.g. 15 minute interval level it could be much greater still. ↩
-
In this regard maybe George Orwell was right (in Animal Farm) with “Four legs good, two legs bad!” but probably not: Four of anything should provide better resilience than two. But balancing across two might well be easier ↩

One thought on “Fearful Symmetry”