(Originally posted 2016-09-03.)
I know of no customer who uses the full capacity of a zEC12, let alone a z13? 1 So why do we make them bigger each time?
I should state this post is not in support of any product announcement; It’s just scratching an itch of mine.
I think it’s an interesting topic; I hope you agree.
What Is Bigger?
While this post isn’t exhaustive I think the main aspects are:
- Processor Capacity
- Memory
- I/O Capability
- Number Of LPARs
While I’ll touch on these, as examples, I won’t talk much about engine speed; That’d be a whole other post – if I were to write about it.
Where Are Most Customers?
This is just from my personal customer set, but most of my customers are in the range of 10 – 20 purchased processors per machine. Quite a few have sub-capacity processors.
Generally they have two or three drawers (on z13) or a similar number of books (z196 and zEC12). And most of my customers’ machines are either zEC12 or z13, with a few z196 footprints remaining.
Memory-wise, I’m seeing sub-terabyte to several-terabyte configurations, depending mainly on generations.
Customers I work with tend to have two or more machines.
Typically, customers have more than 10 LPARs on a footprint.
I don’t think any of the above is giving away any secrets. And not all customers are like this.
So Why Build Bigger Machines?
There are a number of reasons, which benefit a wide range of customers. Here are some that come to mind.
Scalability
To meaningfully achieve 141 processors (or 10TB of memory) on a single footprint requires good scalability.
I remember, just after the dawn of multiprocessor mainframes, how awful the multiprocessor ratios were. To achieve even modest levels of multiprocessing a lot had to change. And indeed it has, both in software and hardware.
To be able to scale to 141 processors successfully means good multiprocessor ratios are essential. For your 15-way to be feasible, scalability has to be good across the board, all the way up to 141.
The analogy of “the Moon Shot led to non-stick frying pans” is perhaps inappropriate, but the idea that engineering needed for top end machines yields results for smaller machines is sound.
Running Everything On One Surviving Footprint
Bad stuff happens thankfully rarely to mainframe footprints, but when it does customers need to run their high-importance workloads somewhere.
One of the scenarios wise customers plan for is running (the bulk of) two machines’ worth of work on one. Under those circumstances a normally, for example, 20-way might need to become a 35-way. And be effective at it.
So your operating range might need, in an emergency, to be much higher up the scale.
But it’s not just the “machine gone” scenario that has to be catered for. Indeed a subset of the drawers 2 in a machine might need to be taken out of service. Then you’d still want to run on the surviving drawers. So, a more powerful physical machine is a good thing, under those circumstances. 3
Unexpected Demand
While the economics of unexpected demand might not be nice, the inability to support a sudden massive increase in workload is even worse.
Most customers I know could grow their workload several times over and still be contained within the same number of footprints.
The trick is to avoid derailment factors. Perhaps “wargaming” massive growth scenarios should be seen in the same light as Disaster Recovery tests.
Two examples:
- The use of the various capacity-on-demand capabilities.
- Middleware scalability e.g. CICS QR TCB.
LPAR Limits
I know customers for whom the (pre-z13) limit of 60 LPARs on a footprint was a real limitation. These are mostly outsourcers.
Several use zVM but it would be nice not to have to 4.
I would say a prerequisite to raising the limit to 85 (on z13) was raising the limit on the number of configurable processors way past that. In the distant past I was involved in a Critsit with very large numbers of z/OS images on a footprint.
LPAR design is, of course, critical in this. And Hiperdispatch helps.
Memory
Physically installing memory is one thing; Making it perform is quite another.
For example, we’ve several times changed the fundamentals of memory management in z/OS over the years. 5
But note the continuing evolution of the way middleware uses memory.
Also note the way memory pricing has substantially improved over the years.
Closing Thoughts
Workloads are generally growing quite rapidly, mainly through two factors:
- Increasing business volumes
- More being done with each datdatum
So what might today seem very large might seem much more modest going forward.
I’ve touched on more than just CPU because configuring systems in a balanced way is important. And you can see we pay attention to that in the following graphic.
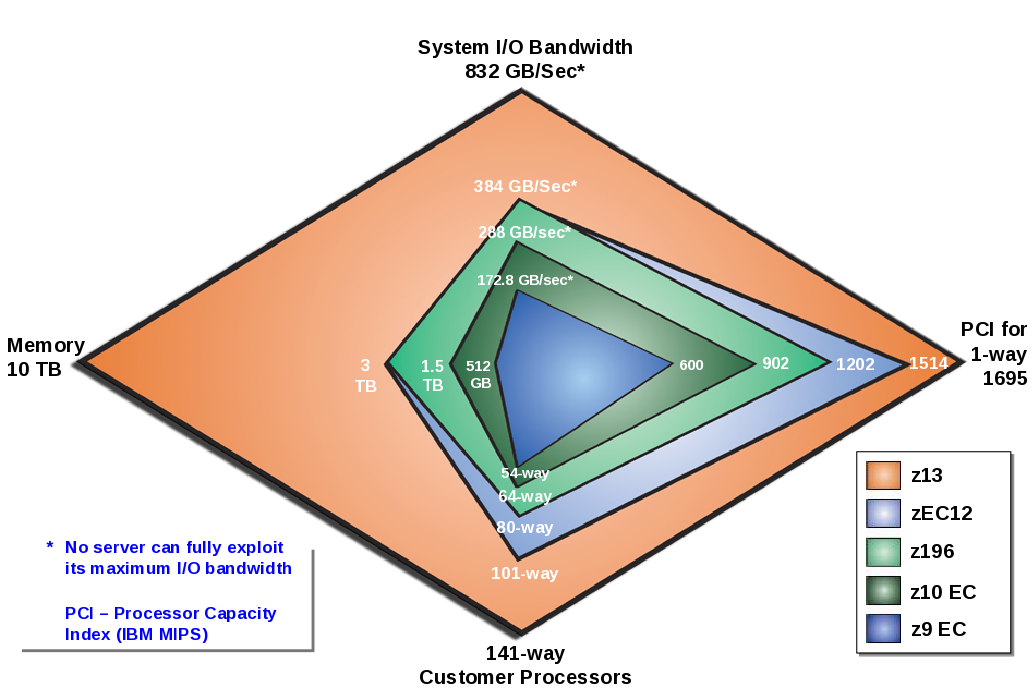
This polar chart is for z13 and it shows how over the generations growth has been across all aspects.
To be specific about CPU, the following chart shows steady growth.
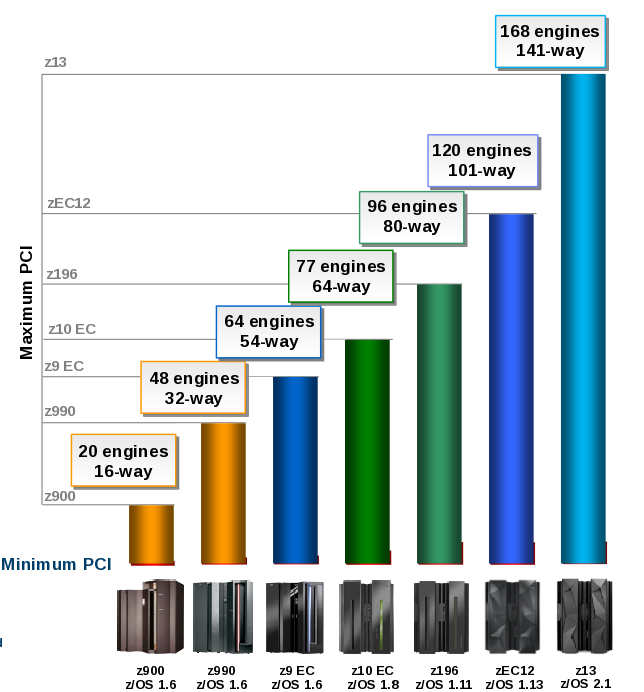
(By the way these two charts were sourced from the most excellent TLLB (Technical Leadership Library).)
We’ve come a long way!
-
I’m sure there are some fully-configured machines in the world, but I’ve yet to encounter them personally. ↩
-
Or books if you are on a machine prior to z13. ↩
-
As an aside, the first physically-partitionable machine I remember was the 3084-QX; It could be split into two independent 2-ways. I’m not sure if this ever had to be done to rescue one half. ↩
-
This is not an anti-zVM statement, of course. ↩
-
Are you still using UIC for much? If so please stop. ↩

One thought on “Why Do We Keep Building Bigger Machines?”