(Originally posted 2012-06-30.)
The CICS Monitor Trace SMF Record (Type 110) has got to be one of the most complicated SMF records in existence – and for good reason.
Which is precisely why I’m not going to attempt to process the raw records in my code. (And why PMCICS doesn’t support releases after a certain point.)
But the "and for good reason" hints at the fact I think this is a tremendously valuable type of instrumentation – because it goes down to the individual transaction instance level.
You’ll have seen from He Picks On CICS I think CICS is a very interesting product to work with, performancewise. (And one day soon I hope to get to play with it from an Application Programming perspective.)
In that post I briefly mentioned CICS Performance Analyzer (CICS PA) – which I’ve spent a lot of time with recently. I like it a lot and the reports (and CSV files) it produces have been very helpful. Not least because it helps sort out the nested components of transaction response time.
In this post, however, I want to outline another approach. If you don’t have (and can’t get) CICS PA this might help you. It might also inspire you if you want to do some custom reporting that CICS PA doesn’t do. (In skilled hands maybe CICS PA will do what my experiment below did. If so it’ll probably do it better.) This approach is to use standard CICS tools and DFSORT to process individual 110 records…
Standard CICS Tools
I’m using two CICS tools. They are both distributed in the SDFHLOAD load library, so if you have CICS you have them. They are:
- DFHMNDUP – which creates CICS Dictionary records, essential to processing Monitor Trace records. This is in SDFHLOAD but not SDFHSAMP but I actually don’t need to know how it works or to modify it. It’s A Kind Of Magic 🙂
- DFH$MOLS – which reads (and decompresses) Monitor Trace records and provides a sample report. It also can create a one-output-record-per-input-record data set. It is in SDFHSAMP – which proved crucial as I needed to know how it works.
DFSORT
We all know (and I hope love 🙂 ) DFSORT and ICETOOL.
Putting It All Together
DFH$MOLS needs Dictionary Records for every CICS region – because these records tell it how to process the records. Because you can tailor Monitor Trace records from a region using its Monitor Control Table (MCT) DFH$MOLS can’t assume they’re in a totally standard format. (Actually I see fewer customers tailoring their MCTs, perhaps because there’s less emphasis on space minimisation.) I said at the outset the record is complicated and this is part of the good reason why.
So, prior to running DFH$MOLS I ran DFHMNDUP once for each CICS region. (From Type 30 I already know the jobnames for the regions and the CICS region names happen to be the same – as is often the case.) Though you can feed in the MCT for a region I didn’t need to – because the set of data I’m working with is from a customer who doesn’t tailor their MCTs. So I ended up with five Dictionary Record data sets – each with one record in. (This customer has a single TOR, three AORs and a FOR.)
When running DFH$MOLS I concatenated these five Dictionary Record data sets ahead of the Monitor Trace data set. You have to do it in this order so the Dictionary Record for a region precedes all the Monitor Trace ones for the same region.
While DFH$MOLS can produce formatted reports I wanted to create raw records with the fields in fixed positions. (You can tell where this is headed.) So I specified UNLOAD LOCAL. The "LOCAL" is quite important: It ensures timestamps are in the local timezone. Otherwise timestamps are in GMT. (I actually did go down this "blind alley" first time round.)
Processing was surprisingly swift and the end-result was a data set with records reliably laid out the way I needed them: I’m out of the game of worrying about record formats and record compression etc. Result! 🙂
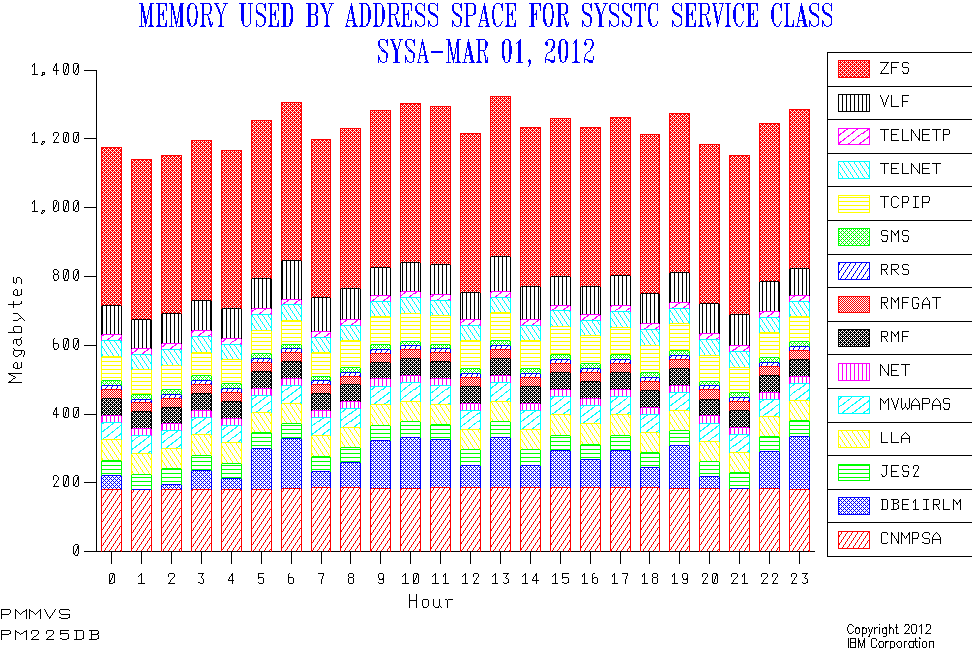
The goal of this experiment was to produce a file with one record per minute – for a single transaction in a single region. The record contains three pieces of information:
- Time of the minute – e.g. "15:30".
- Transactions per second – averaged across that minute.
- Average response time – in milliseconds.
In fact I could’ve formatted these all differently (and summarised differently). So I could’ve used tenths of milliseconds (almost standard – "decimils" or "hectomics"?) and summarised by the second, as two examples.
As I mentioned before I needed to understand some aspects of how DFH$MOLS works – so I read the Assembler source. I’ll admit to not being very familiar with the details of Insert Under Mask (ICM) but it turned out to be important…
The response time for a transaction is given by subtracting the raw record’s start and end times – according to the code. These turn out to be the middle 4 bytes of a STCK (not "E") value. Following the chain of logic further back – and I won’t bore you with the details – it turned out the value is in 16 microsecond units. With DFSORT Arithmetic operators it’s easy to translate that into milliseconds – but best done after summing and piding by the number of transactions.
The timestamp for a transaction is of the form X’02012100′ followed by a value in hundredths of seconds. Again quite easy to turn into something useful in DFSORT. (This time I didn’t need the DFH$MOLS source to tell me this – I browsed the DFH$MOLS output in Hex mode and it was readily apparent.) As I said before my first go was without the "LOCAL" option so the timestamps were from a different time of day and it was obviously GMT. With "LOCAL" I could see it all coming right.
There Be Dragons
The above is quite straightforward – even if the bits about ICM and timestamps left you cold. 🙂 But there are some issues worth noting…
I used the CICS 650 (externally TS 3.2) libraries. This was fine as the records are from TS 3.2 CICS regions. This isn’t generally a stable thing to do – as everything in the process could change from release to release. So run the right DFHMNDUP – if you need that step. Also run the right DFH$MOLS.
In CICS TS 3.2 timestamp fields were widened from 8 bytes to 12. As this web page says DFH$MOLS got it right and the UNLOAD format is still the same as before. Critical, therefore that you have the right DFH$MOLS release.
While I don’t expect the timestamps to get widened again any time soon, there might be further similar changes going forwards. So, to repeat, make sure you’re using the right DFH$MOLS (and DFHMNDUP).
I’m sure there are other dragons but they haven’t singed my cardie yet. 🙂
What Next?
I started to create a DFSORT Symbols mapping of the output of DFH$MOLS UNLOAD but – for reasons of time – only managed to get the first few dozen fields mapped. Sufficient to do my "day job". I could extend that – and it might make a nice sample.
I could publish my DFSORT experimental case as a sample – possibly building on the Symbols deck. I could try and keep track of the twists and turns of the UNLOAD records – using (for example) IFTHEN processing. I’m really not missioned to do that. 😦
I could develop some more examples. Again, I’m not missioned to do that. 😦
I hope this post has encouraged some of you to experiment with this approach.
What I’m going to really do next is explain the following:
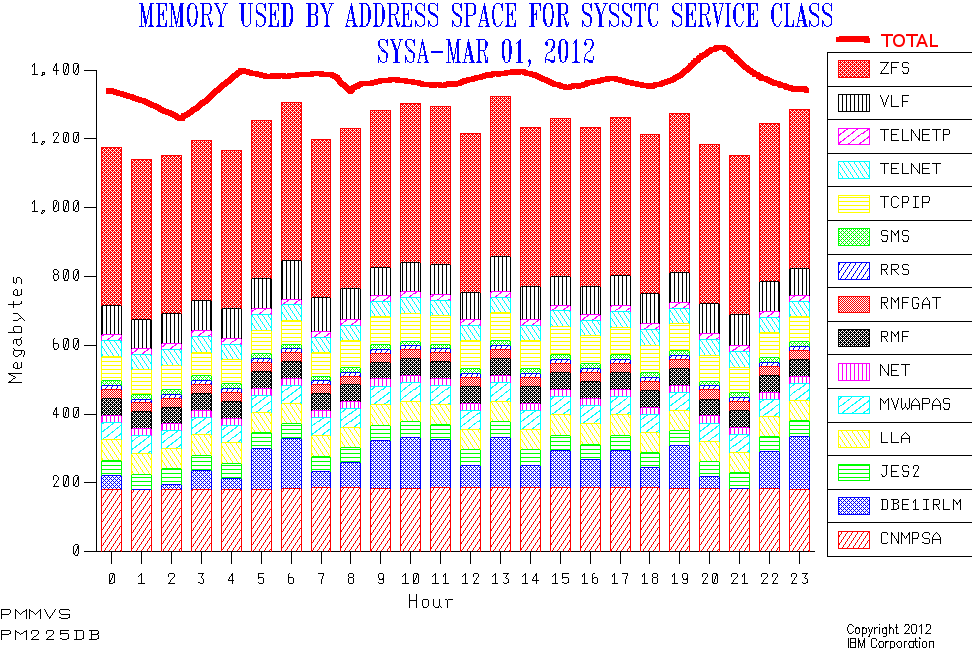
For the first 45 minutes or so the transaction rate stays more or less constant but the response time is all over the place, including some minutes where it spikes to huge (but realistic) values. Then, suddenly, the response time settles down to a low value – and the transaction rate remains more or less the same as it was before. And stays that way to the end of the data.
I think I have an explanation: From RMF I can see certain things awry until about that point (with the standard 15-minute granularity). To really explain it at the transaction level would take a more detailed analysis. Fortunately I can do this with the DFH$MOLS output. And CICS PA has already told me which fields are likely to be the most useful…