(Originally posted 2013-10-20.)
While writing
Creating JSON with DFSORT
I realised one statement in particular is difficult to read and maintain.
It’s this one:
INREC IFTHEN=(WHEN=INIT,BUILD=(SEQNUM,4,BI,
C'{"name": "',NAME,C'","number": "',NUMBER,C'"}')),
IFTHEN=(WHEN=(1,4,BI,GT,+1),BUILD=(2X,C',',5,70)),
IFTHEN=(WHEN=(1,4,BI,EQ,+1),BUILD=(2X,5,70))
It’s not the first one that’s become complicated:
Increasingly people are realising the power of what you can do with DFSORT – especially if you use multiple stages with IFTHEN.
So complexity can become a real issue.
This post is the result of some thinking about how to make developing, reading and maintaining DFSORT applications a little easier.
(And everything I say here is applicable to ICETOOL as well.)
In a nutshell:
- Map the input records with symbols.
- Use symbols for intermediate fields.
- Consider symbols for combined fields.
- Use indentation.
- Build applications from the front to the back in stages.
- Consider using “dummy” IFTHEN stages.
- Use OUTFIL SAVE to avoid losing records.
The rest of this post expands on these.
Map The Input Records With Symbols
Whether you use COBDFSYM (in
Smart DFSORT Tricks)
to map COBOL copybooks
or code your own by hand you should map the input records using DFSORT symbols.
This makes the DFSORT invocation much more readable and a little more maintainable.
That’s actually what I did for the example in
Creating JSON with DFSORT
and if it’s readable that would largely be why.
(On COBDFSYM I wrote about it further in
“Chapter 23.4.1 Converting COBOL copybooks to DFSORT symbols” of
SG24–7779 Batch Modernization on z/OS.)
Use Symbols For Intermediate Fields
If you have, say, two fields NAME and NUMBER in your input record and you move them around or reformat them or otherwise mess with them consider remapping the modified record.
Code
POSITION,1
to reset the Symbols pointer and then start mapping the modified record.
Here’s something I tend to do:
If the original field is called NAME I create a new field in the remapping called _NAME.
Similarly NUMBER becomes _NUMBER.
If I modify them again they become
__NAME and
__NUMBER.
And so on.
(By the way the underscore characters in the above are written in Markdown by prefixing them with a backslash.
I learnt that the hard way.)
Consider Symbols For Combined Fields.
If you are manipulating sets of fields consider using a symbol to describe them as a group.
For example you might have formatted an intermediate form of the record with NAME followed by a blank followed by NUMBER.
The Symbols deck might look like:
_NAME,*,8,CH
SKIP,1
_NUMBER,*,8,CH
But you could code an additional symbol:
_NAME_AND_NUM,*,17,CH
_NAME,=,8,CH
SKIP,1
_NUMBER,*,8,CH
And then you can use it as a combined field.
The trick here is to use = to specify remapping.
It positions the Symbols cursor back to the start of the first field.
In general * and = are very handy in Symbols decks.
In brief
- * in the position field means the symbol’s position is just after the end of the previous symbol.
- = in the position field means it’s at the beginning.
- = in the length field means use the same length as the previous symbol’s.
- = in the type field means use the same type as the previous symbol’s.
Use these wherever you can and it should help maintainability.
Use Indentation
Instead of coding
...
IFTHEN=(WHEN=INIT,BUILD=( ... )),
IFTHEN=(WHEN=(...),FINDREP=(...)),
...
try coding something like
...
IFTHEN=(WHEN=INIT,
BUILD=(...)),
IFTHEN=(WHEN=(...),
FINDREP=(...)),
...
and it’ll be a little clearer.
You might also want to do something like
INREC FIELDS=(NAME,
RANK,
NUMBER,EDIT=(IIT),
...
indenting the fields where possible and putting each on its own line.
(You could indent the EDIT in the above but I think that’s going too far.)
Build Applications From The Front To The Back In Stages
Sometimes – and the past few days have been a good example of this –
it takes a long time to debug a DFSORT application.
The main reason is not understanding how the various stages – whether INCLUDE, OMIT, INREC, SORT, SUM, COPY, MERGE, or OUTFIL fit together. (And I’ve probably missed one or two out.)
It’s even more complex with IFTHEN.
So I recommend building up the set of instructions, and within them IFTHEN stages, slowly.
Check the output at each point is what you expect – before you build the next stage (which relies on it).
It sounds obvious but I labour the point as this stuff is getting complex and it’s easy to make mistakes.
(Most of these are fuzzy understandings of what DFSORT will do.)
Consider Using “Dummy” IFTHEN Stages
This is a minor point and might be slightly controversial.
Don’t do it in Production if you’re squeezing every last ounce of performance out of the application –
but I seriously doubt it’ll be a problem.
Consider the statement:
INREC
IFTHEN=(WHEN=INIT,
BUILD=(...))
The bad news is it’s not legal DFSORT syntax and you’ll get a syntax error.
The following, however, is legal:
INREC IFTHEN=(WHEN=INIT,OVERLAY=(5:5,1)),
IFTHEN=(WHEN=INIT,
BUILD=(...))
The first WHEN=INIT actually doesn’t change any records.
Well it does but in a null fashion:
It replaces the byte at position 5 with the contents of the byte at position 5. 🙂
The net effect is to leave the record unchanged.
If you can’t stand the first effective IFTHEN not being indented then this gets round it.
More seriously you can move the effective IFTHENs around without having to mess with indentation.
As I said this is unlikely to affect performance.
But if you think this trick obscure don’t use it.
I just think it helps with maintaining indentation.
Use OUTFIL SAVE To Avoid Losing Records
If you are routing different records to different OUTFIL destinations – using OUTFIL’s own INCLUDE or OMIT parameters – it can get complicated to ensure all the records go somewhere.
OUTFIL SAVE routes the records that don’t meet any previous OUTFIL INCLUDE/OMIT criteria to another DD.
This saves coding complex “everything else” rules – even if Augustus De Morgan
did found your Maths Department and you do understand
Relation Algebra. 🙂
Note: The records thrown away by INCLUDE or OMIT statements can’t be recovered using OUTFIL SAVE.
As I say, writing the previous post reminded me of how ungainly the coding can be.
But I didn’t think a list of techniques to handle that belonged in the same post.
Hence this one.
If you have other DFSORT comprehension and maintainability tricks I’d love to see them.
If you think these aren’t right – especially the last – let me know.
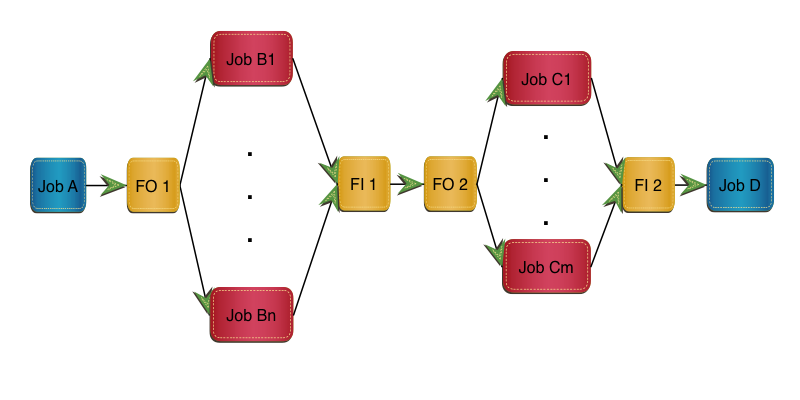 In this implementation Job B is replaced by FO 1, m clones and FI 1.
Job C is replaced by FO 2, n clones and FI 2.
In this implementation Job B is replaced by FO 1, m clones and FI 1.
Job C is replaced by FO 2, n clones and FI 2.
