(Originally posted 2017-07-08.)
I’m writing this under a lovely cherry tree in my back garden, in cool shade on a warm summer’s day. Before you complain “that ain’t working” I’ll just point out this is on a Saturday afternoon. 🙂 And the “air cooling” is what makes this post possible. 🙂
Just this past week I began an experiment. As with all experiments I might continue with it, but I might not; It depends on whether people find it interesting or valuable.
One of the nicest things about my job is when a truly interesting graph or diagram appears in front of me, especially if it’s the result of some programming of mine. This week has been full of such moments, as I’ve developed some new code. (More of that in a different post, I think.)
And the week started with an episode of Mac Power Users talking about screencasting.1
About 10 minutes into the episode I suddenly thought “I could use screencasting to talk about some interesting graphs”. For once, I had the discipline to listen to the rest of the episode before doing something about it. I will admit I was fair chomping at the bit. 🙂
My development approach this week has been the nearest to disciplined I think I’ve ever been. 🙂 It turns out I had four hills to capture. Because I might have to stop with only a few hours’ notice this is a nice characteristic. Each hill took about a day and I promoted into Production after each hill was captured.
Agile? More like Fragile. 🙂
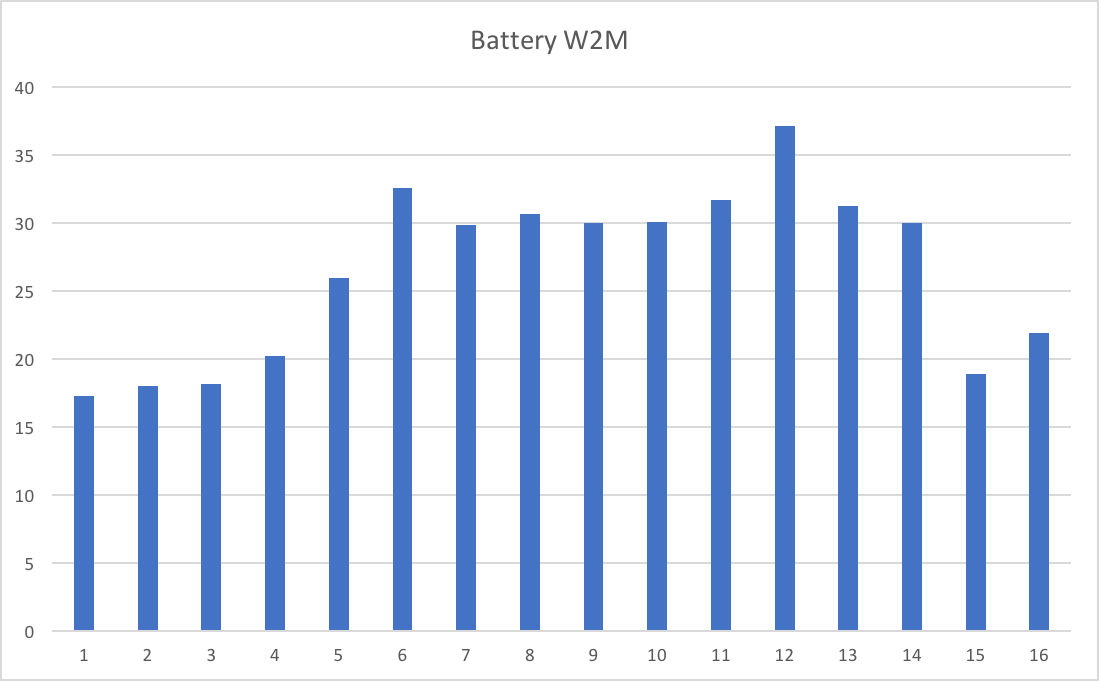
And so after capturing the first hill I recorded my first screencast:
This was pretty basic; I’m just moving the pointer around on a single graph while I talk.
After the second hill I recorded my second:
This time I had three graphs to show, building on the story from Screencast 0.
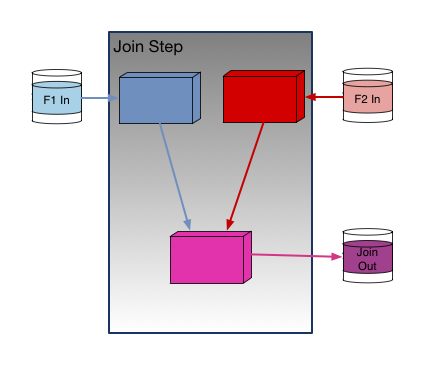
But then I thought I would take one of my “in Production” graphs and annotate it. It’s one that has nothing to do with the first two but one I very commonly use:
Here I used Pixelmator for Mac, which is rather overkill. I take the base graphic (a PNG) and create more graphics with successive annotations. It actually was unwieldy, given I don’t have much experience with Pixelmator.
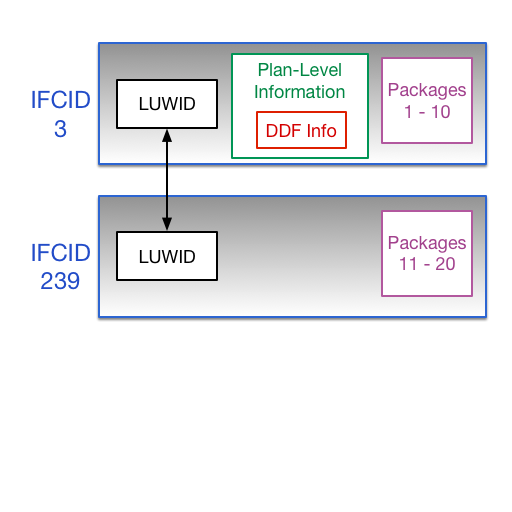
Then I captured a third hill, which led to:
This time I used the much simpler (and built in to Mac OS) Preview to annotate. It did indeed take much less time, though it would be fair to note it’s only a single “base” slide.
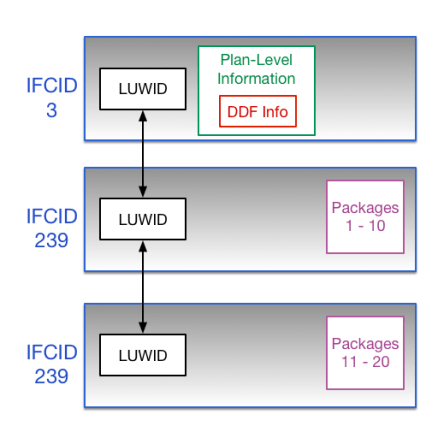
And finally, for now, it was really quick to illustrate the capturing of the fourth hill with:
At this point point I realized my screencasting might be a “thing” so then the question of “materials management” came up. My answer is just to shove each screencast (episode) in its own folder. I feel vaguely organized now. 🙂
Thoughts
It’s occurred to me this is quite a light-weight teaching aid. So when I develop new code I might well use this to explain the value, issues and nuances.
It also occurs to me that anyone – certainly on a Mac – could produce (and share or publish) material like this. And if you had, say, presentation slides to give you might do it this way.
As you can see, I’m experimenting with annotation tools. So far I’ve used two on the Mac – preparing them as static graphics before recording. I also have several on iOS, most notably Pixelmator for iOS and Annotable. What I’m not doing is annotating the video itself. I probably should get round to audio clean up and video editing; I’m not sure how I’ll do that. 2
One stance I deliberately took was to produce short but frequent videos. I think that makes it less daunting to do and possibly more consumable for the viewer.
I don’t know if I’ll commit to keeping on going. Certainly daily (my current rate) seems too aggressive and weekly too infrequent. That depends on the viewership. I certainly think material is going to keep appearing that this medium would be well suited to.
Nobody would call me “camera shy”. 🙂 But the effort of recording and editing pieces to camera seems to me quite high, with little value. This, however is much easier to do. So I don’t think I’m going to do videos with me in them – unless something changes my mind.
This is – to me – a great toe in the water. I hope it is to you, too.
-
To be specific, #384: Screencasting 101 with JF Brissette ↩
-
This, however, isn’t a priority. ↩






{kind=link}