(Originally posted 2015-10-02.)
The last post hit both the “Mainframe” and “Performance” aspects of this blog. This one is firmly in the “Topics” category.[1]
You might’ve noticed a slew of announcements from Apple recently, and iOS 9 and OS X 10.11 “El Capitan” delivery. [2] I’d like to talk here about one feature of iOS 9 that is more useful than it appears at first sight: Slide Over on the iPad.[3]
What Slide Over Is
If you have a modern enough iPad or iPad Mini you can use Slide Over.[4]
In landscape mode (is there any other?) 🙂 you can slide over from the right of the screen to display a vertical list of apps in the right-hand third. It looks like this:[5]
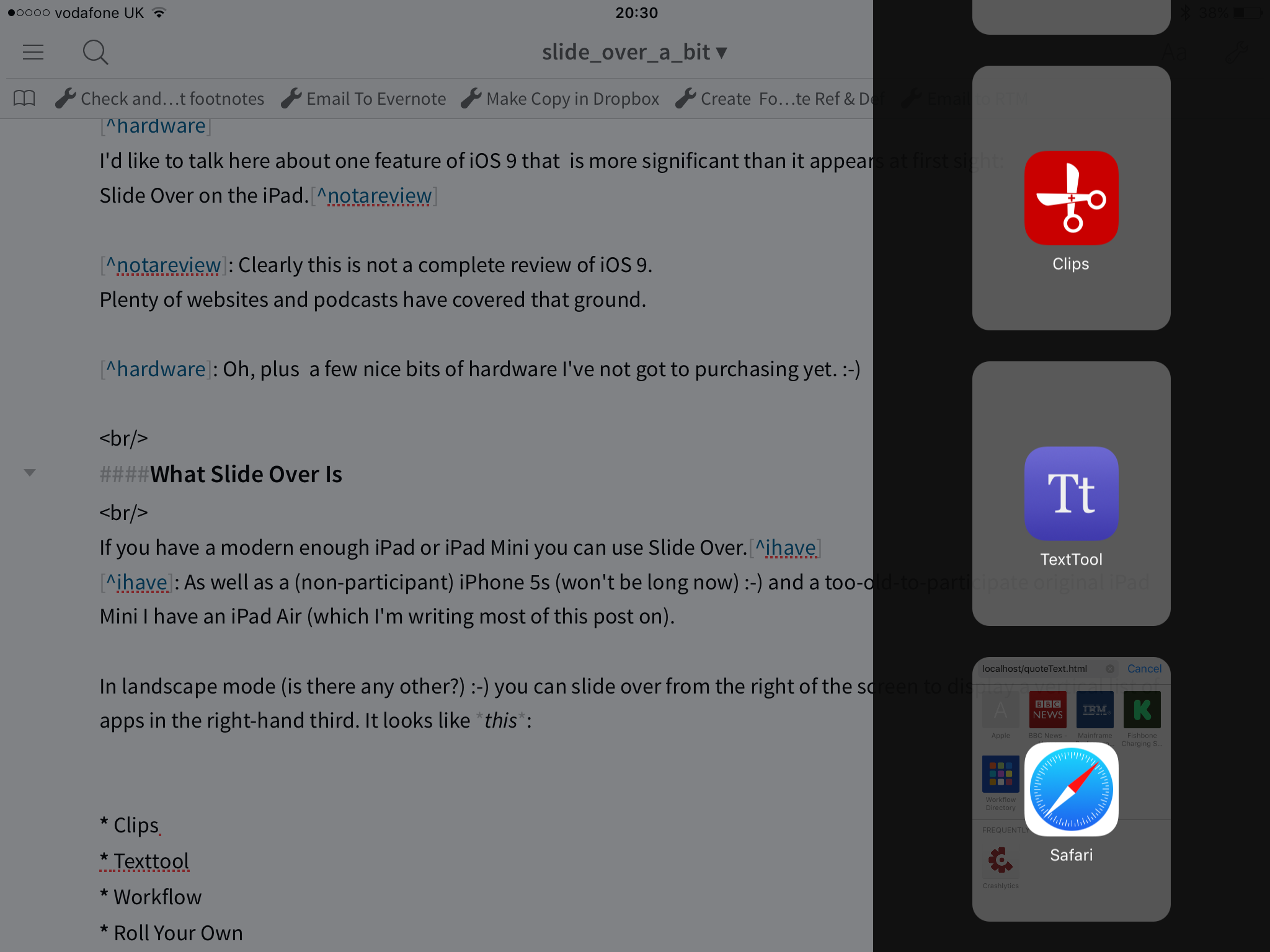
App developers have to explicitly support Slide Over and quite a few have. Apparently it’s not difficult.
You pick an app from the list and the original app (in the left two thirds of the screen) pauses. Tapping in this left area resumes the original app (full screen).
Why Am I Excited About This?
Well, apart from the novelty, there’s a nice use case – which becomes much slicker:
Suppose you’re writing and you want something done to a chunk of text. The first example I stumbled over was extracting some text from a BBC News website article and wrapping it in quotes. I wanted to tweet the text and a link.
The following workflow would suffice:
- Copy the text to the clipboard.
- Slide over and select a tool to paste into that wraps text with quotes.
- Copy the result back to the clipboard
- Paste into the tweet and post.
Actually I did a very similar thing to create the numbered list above – using the List function of Texttool:

In the above I chose the numbered list option you can see – and then pasted the result back in to Editorial.
Notice how Editorial is greyed out while Texttool is in full colour.
So mini apps (or widgets) that process text are a very good use of Slide Over.
Some Ways Of Getting Such Widgets
As I mentioned there are quite a few apps – some from Apple, many not – that show up in Slide View.
Here are some examples.
- Clips – which keeps multiple items you’ve cut to the clipboard for ease of use.
- Texttool – which does simple text transformations.
- Workflow – which allows you to build workflows, as the name suggests.
- Likewise Editorial and Drafts.
- PCalc – a nice calculator.
- Roll Your Own.
In several of these – Workflow, Texttool and Roll Your Own – I’ve succeeded in wrapping pasted in text in quotes.
Rolling My Own
One of the most flexible (and not that difficult) ways of building your own is using bookmarks in Safari to locally hosted web pages.
As an experiment I set up a simple webserver in Pythonista using (the possibly inadvisable) port 80:
# coding: utf-8
import SimpleHTTPServer
import SocketServer
port=80
handler=SimpleHTTPServer.SimpleHTTPRequestHandler
HTTPD=SocketServer.TCPServer(("",port),handler)
HTTPD.serve_forever()
(By the way I just used Texttool in Split View to indent the above code by 4 spaces to get it to format as code in Markdown.)
Anyhow, in the same Pythonista directory I created quoteText.html:
<!doctype html>
<html>
<script>
str=prompt("Throws double quotes round text.\n\nPaste in text.")
if(confirm("Double Quotes?")){
prompt('','"'+str+'"')
}else{
prompt('',"'"+str+"'")
}
</script>
</html>
In Safari I have this bookmarked and Safari can be used in Slide View with it.
In essence I’ve prototyped my own Slide Over text processor. This one wraps in single or double quotes any text you paste into a prompt.
As you can see it’s very simple.
Creating an HTML 5 web app from a remote webserver that stays permanently on the iPad is left as an exercise for the reader. (I’ve done something similar before but, having Pythonista, I didn’t need to for this example.)
It’s Not Quite Perfect
Slide Over is saving me time. But there are some things that could be better:
- I find selecting apps a bit cumbersome: Pinning some, or text-based navigation would help.
- I’d like it to be easier to roll my own.
- I’d like to be able to go direct to bookmarked web pages there (perhaps pinned).
- Cutting and pasting is a cumbersome method of transferring data – particularly if you forget to Cut and use Copy instead. 🙂
But overall I think the “side bar widget” use case for Slide Over is compelling.
I briefly mentioned OS X 10.11 El Capitan. At last it allows you to have two windows up – snapped to either side of the screen. I’m going to experiment with snapping stuff to the right side – in a similar vein. I don’t expect it to work as well. Perhaps the Today view is the analogue.
Fun, eh? 🙂
-
Not that I really feel the need for legitimisation. ↩
-
Oh, plus a few nice bits of hardware I’ve not got to purchasing yet. 🙂 ↩
-
Clearly this is not a complete review of iOS 9. Plenty of websites and podcasts have covered that ground. ↩
-
As well as a (non-participant) iPhone 5s (won’t be long now) 🙂 and a too-old-to-participate original iPad Mini I have an iPad Air (which I’m writing most of this post on). ↩
-
Notice how Safari has greyed-out content rendered, whereas Clips and Texttool don’t, because Safari is already running. ↩